预聚合:为什么 Cube 不仅“能查”,而且“查得快”
如果说语义模型解决的是“口径统一”,那 pre-aggregations 解决的就是“性能可用”。
关键性能结构图
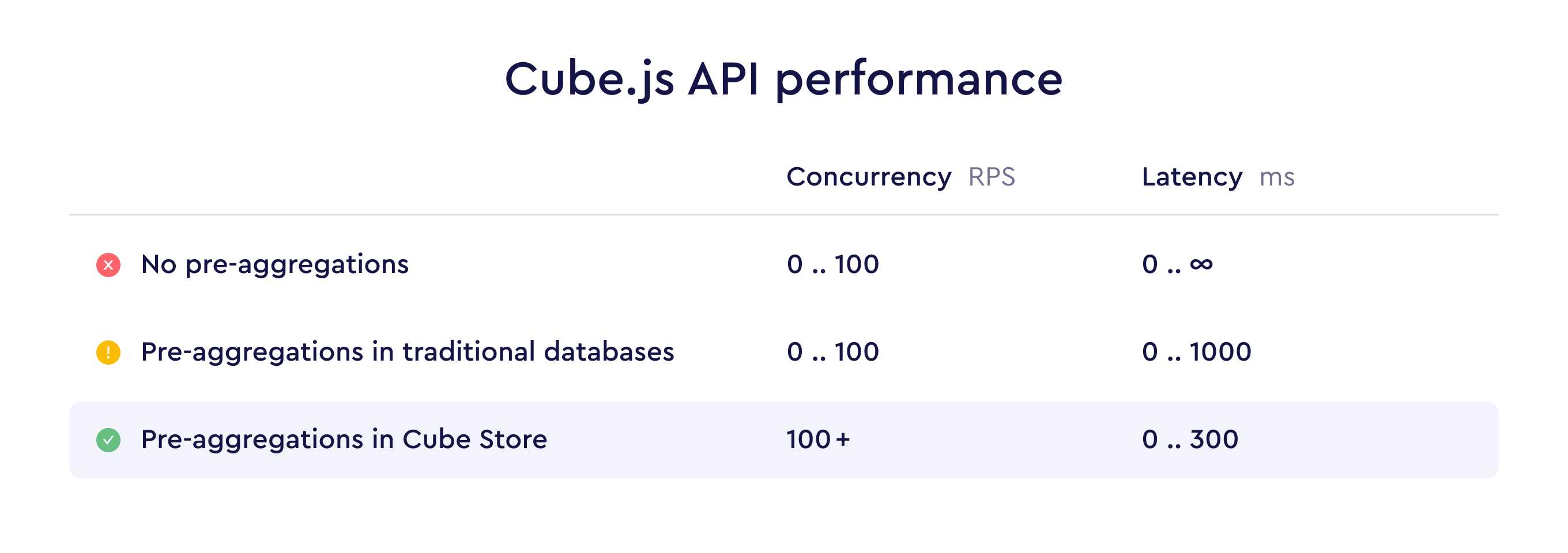
1. 先理解它在 Cube 里的定位
官方文档直接把 pre-aggregations 描述为:
- aggregate awareness 的实现;
- materialized query results;
- Cube 可以分析查询并匹配最优预聚合规则;
- 如果规则可用,则直接使用预聚合而不是查询原始数据。
这说明 pre-aggregations 不是一个“边缘优化”,而是 Cube 的核心能力之一。
2. 为什么 AI / BI 场景都需要它
BI 场景
- 趋势图很多;
- 分组聚合很多;
- 大屏 / Dashboard 会反复加载;
- 用户并发常常不可预测。
AI 场景
- Agent 会多轮追问;
- 同一问题会从多个维度反复切分;
- 会频繁做 exploratory analysis;
- 如果都回源查询,成本很快不可控。
所以语义层不仅要“定义得对”,还要“跑得动”。
3. 一个最小 rollup 例子
pre_aggregations:
- name: orders_by_status_daily
measures:
- count
- total_amount
dimensions:
- status
time_dimension: created_at
granularity: day这个定义的意思是:
- 先按日聚合;
- 同时保留状态维度;
- 预先计算订单数与销售额。
如果后续查询是这个 rollup 的子集,Cube 就更容易直接命中它。
4. 什么查询更容易命中预聚合
一般来说,查询越像下面这类,就越容易命中:
- 时间趋势类;
- 常规分组聚合;
- 指标是 additive measures;
- 维度组合与预聚合设计相近。
5. 为什么 additive measures 很重要
官方文档明确指出,可加性会影响 pre-aggregation matching。
通常更适合 rollup 的 measure 类型包括:
countsumminmaxcount_distinct_approx
而像 avg、复杂计算指标、部分多阶段指标,则需要更谨慎设计。
6. Refresh Key:如何判断预聚合是否过期
Cube 使用 refresh_key 来判断数据是否需要刷新。
时间间隔型
refresh_key:
every: 5 minuteSQL 检测型
refresh_key:
sql: SELECT MAX(created_at) FROM orders文档说明:Cube 会定期检查 refresh key,如果结果变化,就认为需要刷新相关缓存或预聚合。
7. 增量刷新什么时候重要
当你的预聚合基于时间分区,并且数据量很大时,增量刷新非常关键。
典型场景:
- 订单每天新增,但历史月分区基本不变;
- 你只想刷新最近若干天 / 若干月;
- 不希望每次全量重建。
这时可以结合:
partition_granularityincremental: trueupdate_window
来做更高效的刷新策略。
8. Refresh Worker 为什么是生产必备
官方部署文档和缓存文档都明确建议:
- 在生产环境中,背景刷新应由单独的 Refresh Worker 负责;
- 不要把刷新过程完全放在用户请求路径里。
原因很简单:
- 如果刷新发生在前台查询时,用户体验会被拖慢;
- 如果预聚合不能持续保鲜,命中率就会下降;
- 如果租户和预聚合很多,刷新本身也需要独立扩缩容。
9. Rollup-only 模式什么时候有用
文档中提到 CUBEJS_ROLLUP_ONLY。
它的含义是:
- 查询只能使用预聚合;
- 不允许直接回源查询上游数据源。
适合场景:
- 你希望严格控制数仓成本;
- 你希望在线查询绝不打原始数仓;
- 你愿意用更强的预聚合设计换取更稳定的线上 SLA。
10. 给中文教程读者的实战建议
建议 1:先从一个“大而简单”的 rollup 开始
不要一上来设计几十个预聚合。先覆盖最常用的 1~3 条查询路径。
建议 2:优先覆盖高频时间趋势查询
大多数分析产品里,时间趋势都是最常见、最值得预聚合的模式。
建议 3:先做 additive measures
先把 count、sum 这类最稳的指标跑通,再扩展到更复杂场景。
建议 4:配合查询历史做迭代
不是拍脑袋造 pre-aggregations,而是根据真实查询模式逐步优化。
11. 最适合中文读者的理解方式
可以将 pre-aggregations 理解为:
“为最常见的分析问题提前算好结果表,让语义层在运行时做正确匹配。”
这比简单说“物化视图”更贴近 Cube 的工作方式。
一句话总结
pre-aggregations 是 Cube 把语义层做成生产级分析系统的关键:它让高频查询不必每次扫描原始数据,而能以更低延迟、更高并发、更低成本返回结果。