精读:Introducing Cube Store
- 原文:Introducing Cube Store: High concurrency and sub-second latency for any database
- 作者:Igor Lukanin
- 发布时间:2021-04-30
- 原文链接:https://cube.dev/blog/introducing-cubestore

这篇为什么值得读
这篇文章是理解 Cube 性能架构的关键材料。许多人第一次接触 Cube 时,会把它理解为“建模 + API 层”;但如果不理解 Cube Store,就很难充分理解 Cube 为什么能够进入生产分析场景。
性能与架构图
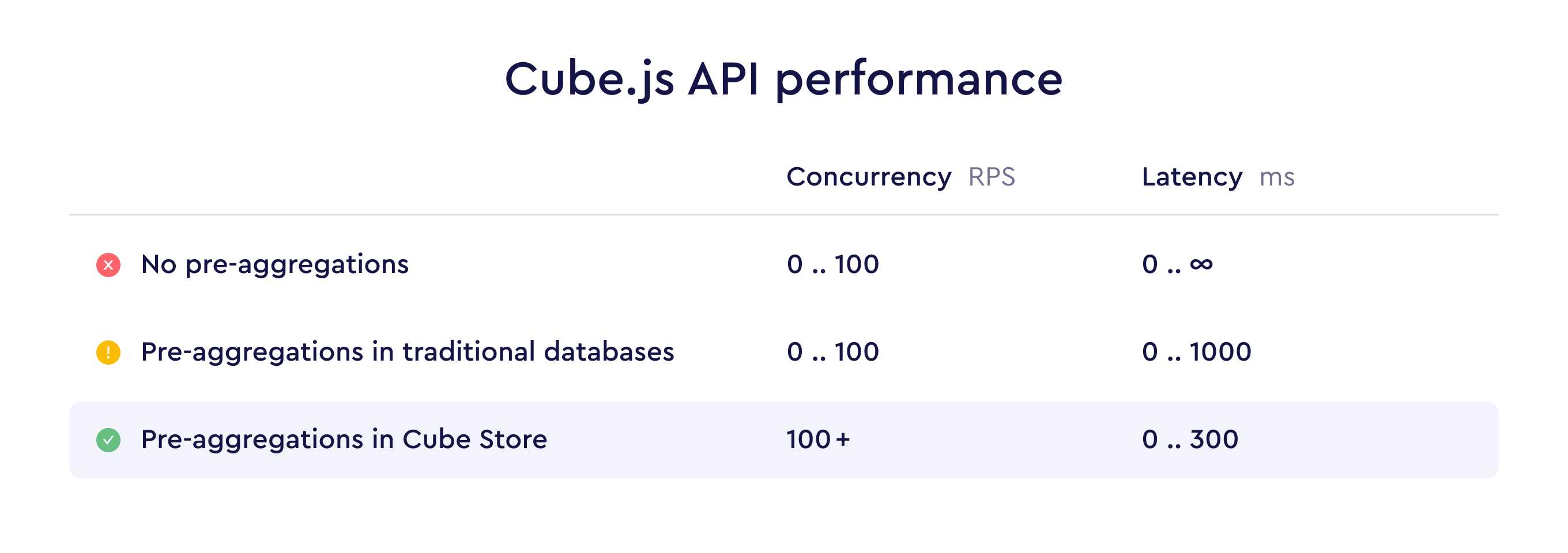
核心观点
1. 仅靠 in-memory cache 和 query queue,不足以支撑生产
原文很清楚地说:最简单的模式下,Cube.js 可以靠内存缓存和查询队列改善性能,但这通常不是最可扩展、也不是最划算的生产方案。
这意味着:
- Cube 从一开始就不是只想做一个“SQL 转发器”;
- 它需要自己拥有更强的分析执行与缓存基础设施。
2. 预聚合才是现实生产中的主要加速手段
文章把 pre-aggregations 说得非常直白:
- 先把源数据预计算、分区、存储、刷新;
- 再让高频查询直接命中这些结果。
这正是 Cube 性能模型的核心,不是附属优化项。
3. 传统数据库作为预聚合存储,会很快成为瓶颈
原文指出了几类痛点:
- 并发不够高;
- 延迟不够低;
- 高基数、分区、跨库 join 等场景表现不好;
- 某些分析特性支持不足。
所以 Cube Store 出现的本质原因是:
需要一个专门为 pre-aggregations 设计的存储与查询层。
4. Cube Store 是分布式、列式、可水平扩展的
文章给出的结构包括:
- router node
- worker nodes
- local / cloud blob storage
这也解释了为什么我们在教程里会把 Cube Store 描述成“预聚合存储与查询引擎”,而不是单纯的 cache。
5. Cube Store 让 Cube 从“逻辑层”进化为“性能底座”
文章明确把 Cube Store 定位为生产推荐方案,并强调:
- 高并发
- 亚秒级延迟
- 跨数据源联邦能力
都因此变得可行。
和本教程哪几章最相关
对中国团队的启发
1. 讲 Cube 时,一定要把“语义层”和“性能层”一起讲
如果只讲语义模型,不讲 Cube Store,读者会误以为 Cube 的价值只在治理,不在运行时能力。
2. 如果你的目标是高并发 API 化分析,Cube Store 几乎是主线组件
尤其当场景涉及:
- Dashboard 高并发加载
- 嵌入式分析
- AI 多轮探索查询
- 云数仓成本敏感
3. 这篇文章也有助于澄清一个常见误解
误解是:
“既然数仓已经很强了,为什么还需要 Cube 自己的存储层?”
文章给出的答案很清楚:数仓擅长统一存储与大规模计算,但不一定擅长 面向高频、小型、交互式分析请求的服务层模式。
我的补充判断
Cube Store 的价值不在于“又造了一个数据库”,而在于它把 Cube 的预聚合体系转化为真正可运营的线上能力。
从这个意义上说,Cube Store 之于 Cube,有点像:
- 编译器后的高性能运行时;
- 语义层后的专用 serving engine。
一句话总结
这篇文章最重要的结论是:Cube Store 让 Cube 不只是“统一语义”,还能以高并发、低延迟、可水平扩展的方式把预聚合真正服务出去。