AI / Agent 场景:为什么 Agent 不应直连原始表
这是整套教程中最关键的章节之一。
关键架构图
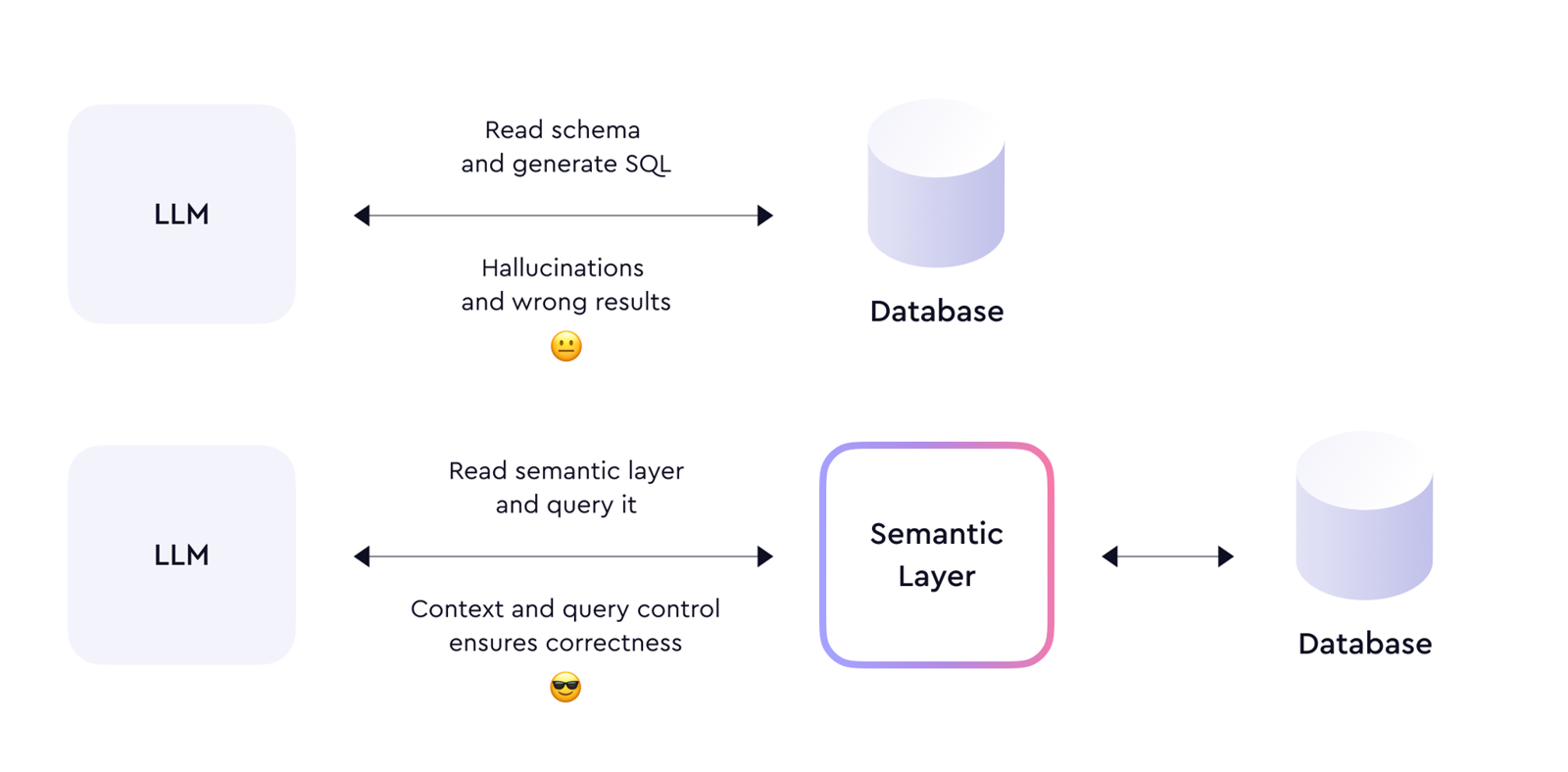
1. Agent 真的会“写 SQL”,但这还不够
今天的大模型和 Agent 框架,已经能在很多情况下生成可执行 SQL。
但在企业级分析场景中,问题并不只在于 SQL 语法:
- 指标口径是否正确;
- join 路径是否正确;
- 维度暴露是否合理;
- 权限是否满足合规要求;
- 查询是否会把数仓打爆;
- 结果是否能与 BI 保持一致。
因此,真正应当被 AI 消费的,不是大量裸表,而是:
一个稳定、受治理、可执行的业务语义接口。
2. Cube 在 Agent 架构中的位置
一个典型架构可以概括为:
text
自然语言问题
↓
LLM / Agent 解析意图
↓
匹配 Cube 中的指标、维度、过滤与时间粒度
↓
调用 Cube API
↓
Cube 编译查询 / 命中预聚合
↓
返回可信结果
↓
Agent 负责解释、追问与可视化这里的责任边界非常清楚:
- LLM / Agent:理解问题、组织查询、解释结果;
- Cube:提供统一语义、权限、性能与数据返回。
更完整的 AI 数据体验架构图
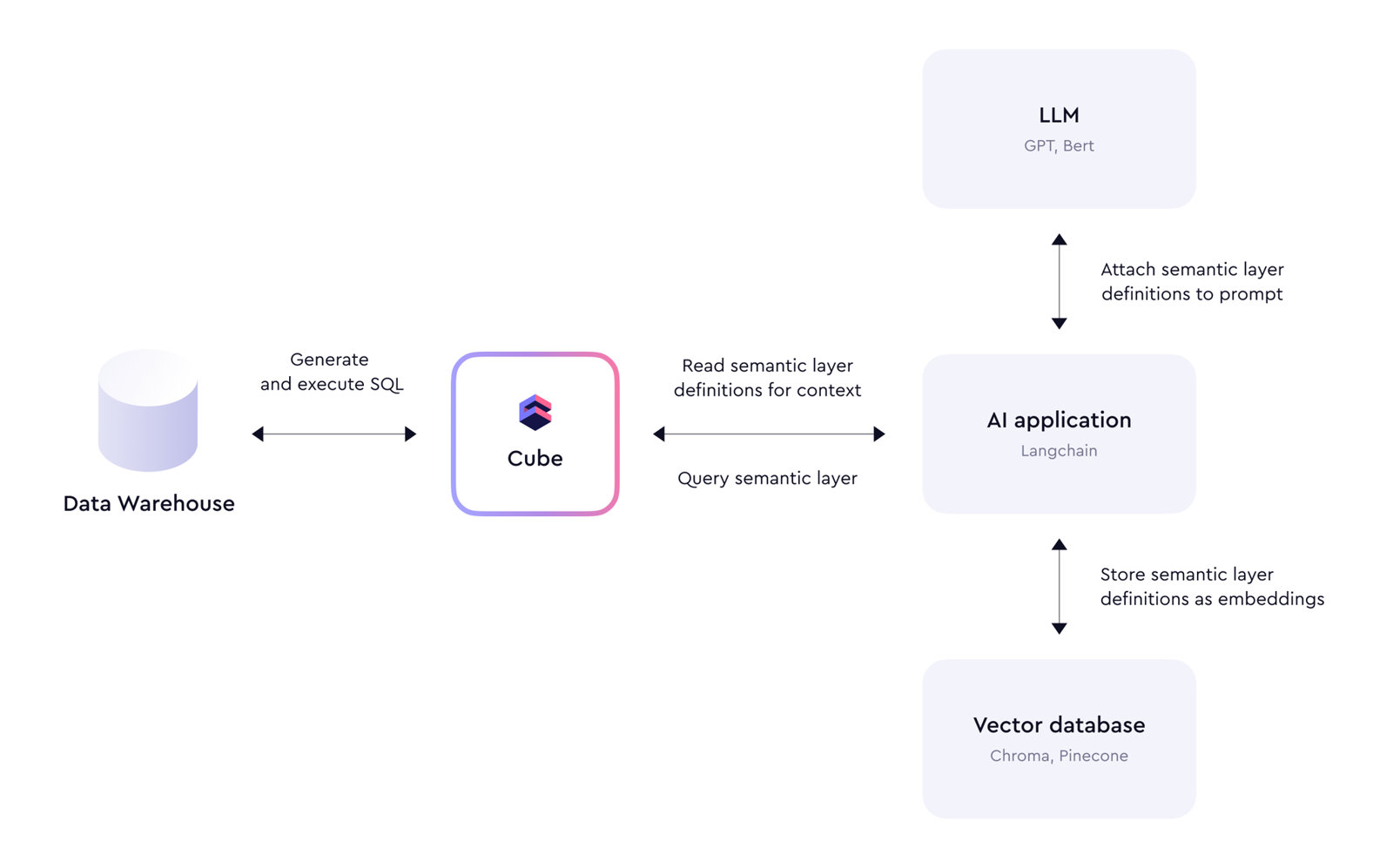
3. 为什么这比直连原始数据稳定得多
问题 1:join 猜错
原始表场景下,Agent 很容易不知道到底该怎么连。
问题 2:口径不一致
原始字段并不等于业务指标。
问题 3:权限不可控
即使 SQL 正确,也可能越权访问不应暴露的数据。
问题 4:性能不可预测
探索式多轮查询会对上游数仓造成持续压力。
Cube 在这四个方面都提供了结构化缓冲层。
4. Agent 最适合通过什么方式接 Cube
方式 A:REST API
优点:
- 易于程序化构造请求;
- JSON 结构清晰;
- 适合作为 tool call 的输出格式。
方式 B:SQL API
优点:
- 对熟悉 SQL 的 Agent / 中间层很自然;
- 可以像数据库一样被消费;
- 适用于 Notebook、BI 以及部分代理式 SQL 工具。
方式 C:MCP
适合:
- 直接与支持 MCP 的 AI 客户端集成;
- 需要更“AI 工具化”的交互体验。
但无论入口是什么,真正的数据治理价值仍然来自底层语义层,而不是协议本身。
5. 中文教程里应该怎么讲“AI 友好”
不要把 Cube 的 AI 价值讲成:
- “它可以自动帮你问数”;
- “它自带一个聊天机器人”;
- “它会替你理解所有业务语义”。
更准确的表述是:
Cube 让 AI 有机会在一套被治理过的业务语义上工作,而不是在混乱原始表上盲目试错。
6. 从团队协作角度看,Cube 还有一个额外价值
如果没有统一语义层,常见情况会变成:
- BI 团队在 Looker / Tableau 里维护一套逻辑;
- 数据应用团队在后端重复实现一套逻辑;
- AI 团队在 Prompt 或工具层又硬编码一套逻辑。
Cube 的价值就在于把这些逻辑尽量收敛到同一个建模层。
7. 这对中国企业尤其重要
许多中国企业在推进智能问数时,主要瓶颈并不在模型能力,而在于:
- 数据口径分散;
- 权限要求严格;
- 数仓成本敏感;
- BI、报表、运营系统、Agent 各自一套定义。
Cube 作为 headless semantic layer,适合成为这些系统之间的统一接口层。
一句话总结
Agent 不应直接连接原始分析表,而应连接一个统一语义层;Cube 的核心价值不是“帮 AI 写 SQL”,而是“给 AI 提供可信、可治理、可加速的数据语义接口”。