为什么 AI 时代更需要 Cube
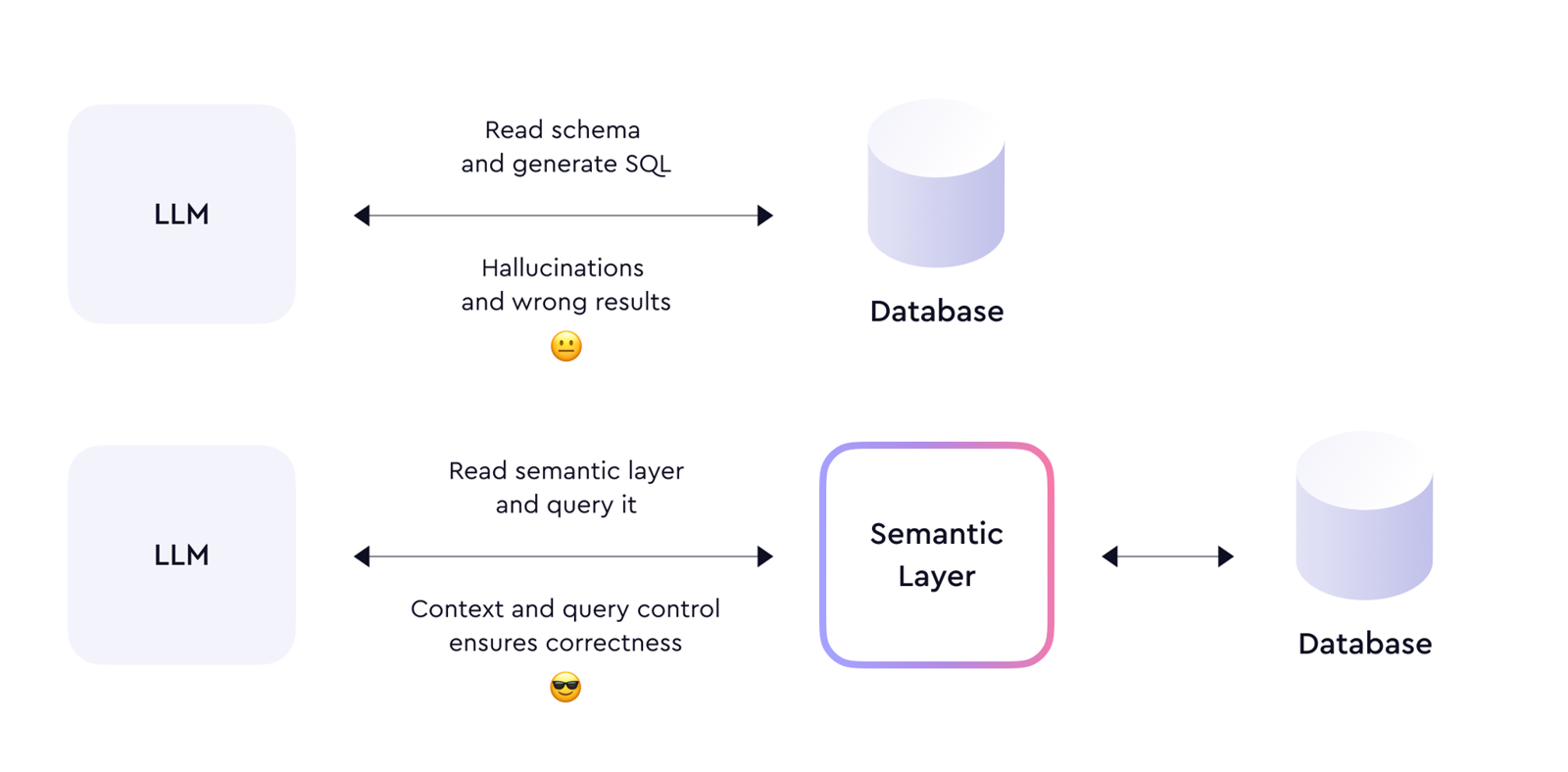
先说结论
在智能问数、分析 Copilot、数据 Agent 逐渐进入真实业务流程之后,企业最缺的往往不是“让模型生成 SQL”的能力,而是:
- 一套稳定的业务指标口径;
- 一套显式可控的 join 路径;
- 一套可治理的权限与数据暴露边界;
- 一套适合交互式分析的缓存与加速层;
- 一套人类和 AI 都能使用的统一查询接口。
Cube 正是围绕这些问题设计的。
智能问数真正难在哪里
很多团队在做智能问数时,一开始会把问题定义为:
“让 LLM 把自然语言翻译成 SQL。”
但在真实企业环境里,真正困难的部分通常不在 SQL 语法,而在业务语义。
例如:
- GMV 是否包含取消订单?
- 收入是否扣除退款?
- 活跃用户到底按登录、下单还是关键事件定义?
- 用户、订单、商品、支付、退款之间到底走哪条 join 路径?
- 当前用户能否看到全公司数据,还是只能看到自己所在国家 / 大区 / 部门?
这些问题都不是 LLM 靠“语言能力”自动猜对的。
Cube 的核心思路
Cube 的做法不是让每个消费者自己理解原始表,而是先建设一层 统一语义层:
原始数据库 / 数仓 / 湖仓 / OLAP 引擎
↓
Cube Semantic Layer
- measures
- dimensions
- joins
- segments
- access policies
- pre-aggregations
↓
BI / Dashboard / App / AI Agent / Notebook这样做的结果是:
- 人类用户和 AI Agent 访问的是 同一套业务语义;
- 查询表达从“原始表字段”切换成“指标 + 维度 + 时间 + 过滤条件”;
- 查询性能不再完全依赖底层数仓,而可以借助预聚合与缓存优化。
更完整的 AI 架构图
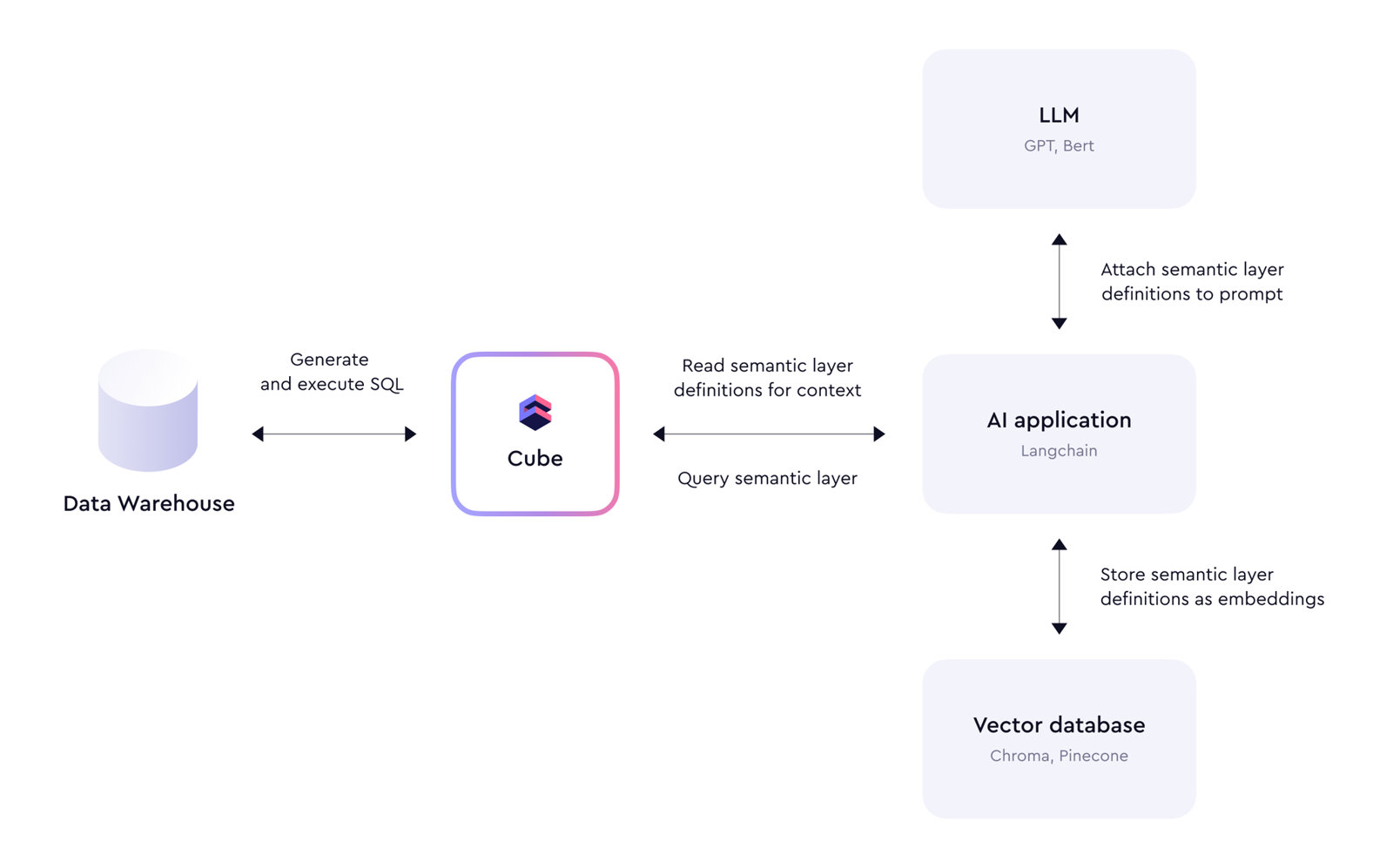
Cube 的官方定位
根据 Cube GitHub README(核对日期:2026-05-22),Cube Core 的定位是:
- open-source semantic layer;
- 统一定义 metrics、dimensions、joins、access rules;
- 通过 SQL、REST、GraphQL 对外暴露;
- 可供 BI tools、custom applications、AI agents 共同消费。
这意味着 Cube 不是传统 BI 前端,也不是单纯的 Text2SQL 工具,而是:
语义定义层 + 查询编译层 + API 层 + 缓存 / 预聚合加速层
为什么这在 AI 时代更关键
1. 人和 Agent 共用一套语义
传统语义层常常被锁在某个 BI 工具内部。Cube 的 headless 特性让它可以作为独立语义层被多个系统复用:
- BI 工具查它;
- Dashboard 查它;
- 嵌入式数据应用查它;
- AI Agent 也查它。
2. Agent 更需要“治理过的数据接口”
Agent 并不应该直接面对一堆原始表名,例如:
ods_order_detail_v3
fact_payment_refund_daily
user_dim_snapshot_202604更合理的方式是让它面对:
orders.count
orders.total_amount
customers.region
products.category也就是已经被建模、治理、授权过的语义对象。
3. Agent 的访问模式更依赖缓存与加速
Agent 与传统 BI 的一个明显差别是:
- 会连续追问;
- 会探索多个角度;
- 会做分步分析;
- 会频繁重复相似查询。
如果所有查询都直打数仓,成本与延迟都很高。Cube 的 in-memory cache 与 pre-aggregations 就会变得非常重要。
Cube 特别适合哪些 AI 场景
- 智能问数;
- 分析 Agent;
- 面向运营 / 销售 / 财务的业务数据助手;
- 面向客户的嵌入式分析应用;
- 需要“同一指标口径”同时服务 BI 和 AI 的企业数据平台。
也要注意它不是什么
Cube 很强,但它并不适合被理解为:
- 通用知识图谱数据库;
- RAG 文档知识库;
- 业务工作流引擎;
- 直接抓第三方 REST / GraphQL API 的聚合平台。
Cube 官方文档明确说明:Cube 主要面向 可 SQL 查询的数据源,不是为直接获取 REST / GraphQL / 其他 API 数据设计的。
Cube 在智能问数架构中的位置
自然语言问题
↓
LLM / Agent 解析意图
↓
匹配指标、维度、过滤条件、时间粒度
↓
调用 Cube REST / SQL / GraphQL API
↓
Cube 编译查询并命中缓存 / 预聚合
↓
返回可信结果
↓
Agent 负责解释、总结、追问和可视化这里最关键的一点是:
Cube 不负责“理解所有自然语言”,它负责给 AI 一个稳定、受治理、可执行的数据语义接口。
一句话总结
如果说过去语义层主要是为了 BI 指标统一,那么在 AI 时代,语义层更重要的作用变成了:
让人类和 AI Agent 都能通过同一套业务语义访问结构化数据,并且在性能、权限与口径上保持一致。