Cube 架构总览
本文旨在帮助你建立对 Cube 的整体技术认知。
官方架构图
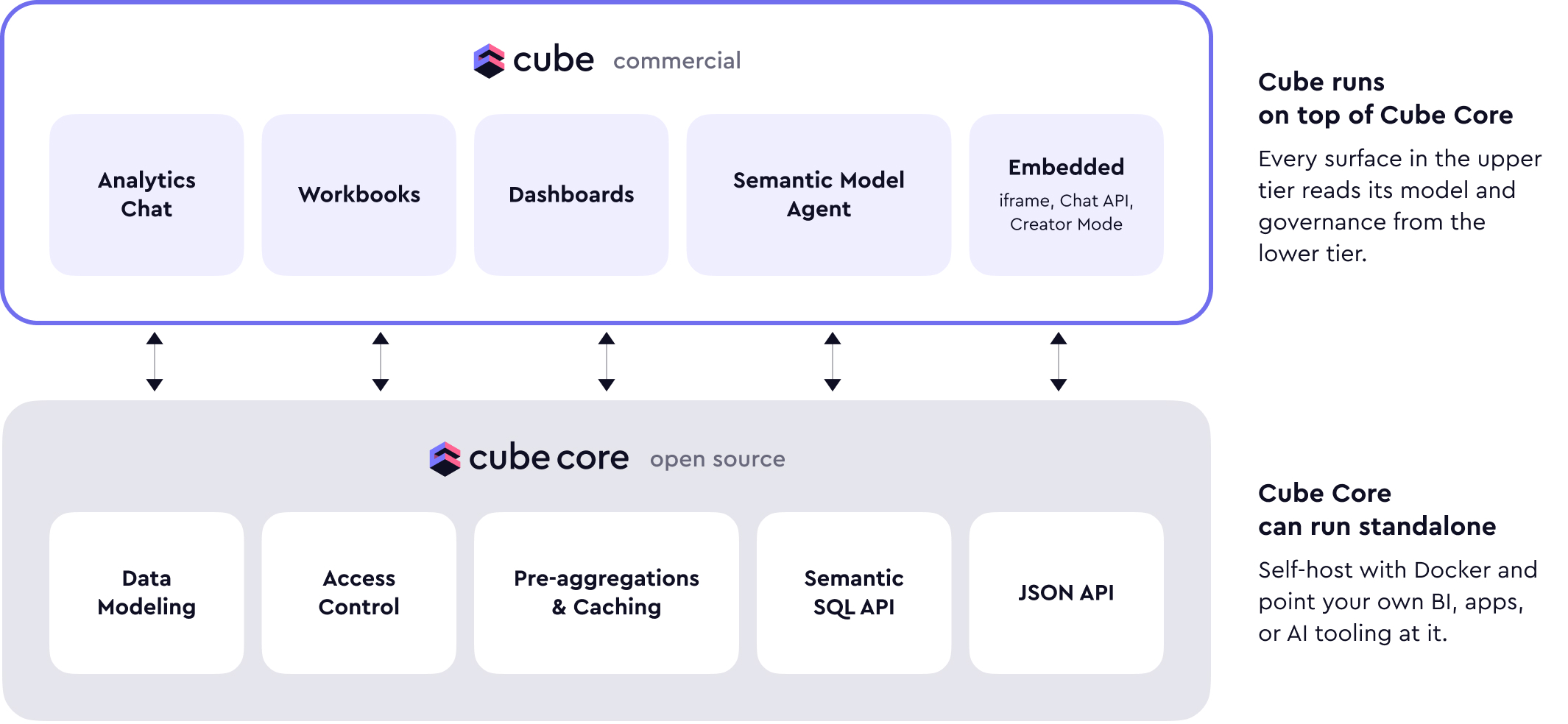
总体结构示意
Cube 的总体结构可以概括如下:
BI / Dashboard / App / Notebook / AI Agent
│
SQL / REST / GraphQL API
│
API Instances
│
Semantic Model + Query Planning
│
Cache / Pre-aggregations Matching
│ │
│ │
Cube Store Raw SQL Query
│ │
Pre-aggregated Data Warehouse / Database
│
Refresh Worker这个架构背后有四个关键层次:
- 语义建模层:定义业务对象、指标、维度、关系与权限;
- 查询编译层:把语义查询转换为底层可执行查询;
- 缓存与预聚合层:加速高频分析查询;
- API 层:向不同消费端统一暴露接口。
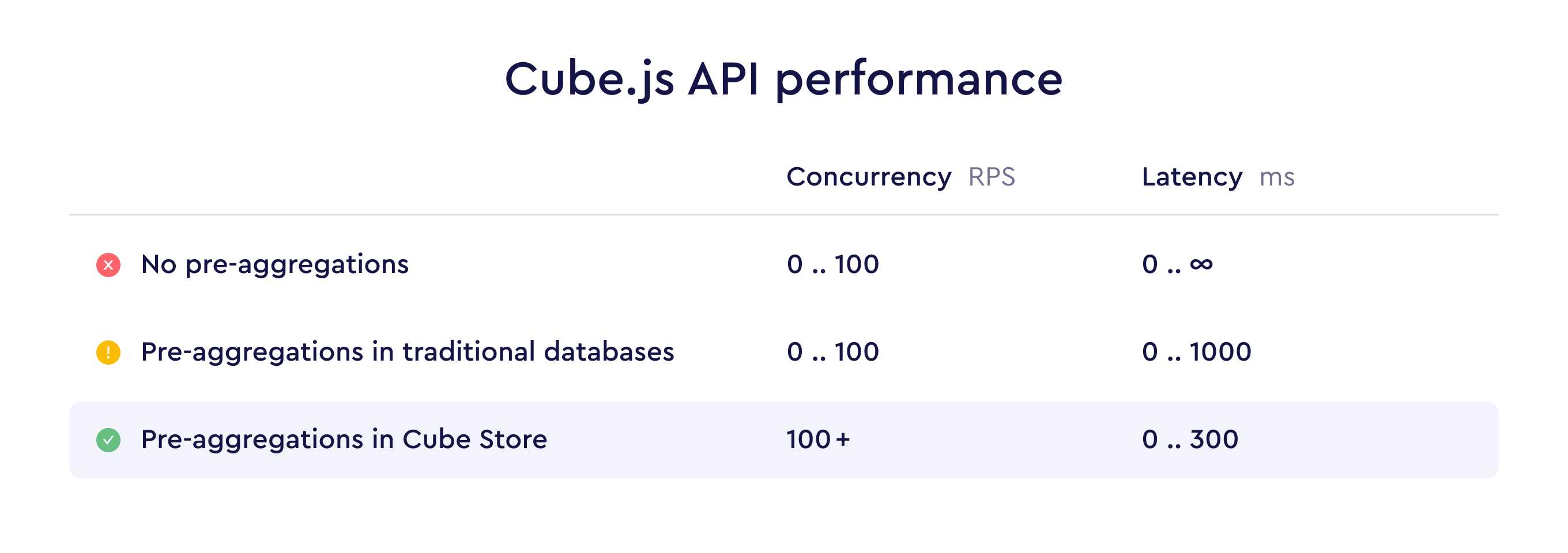
与性能相关的结构图
1. 数据源层:Cube 面向 SQL 数据源
Cube 官方文档对这一点说得非常明确:
- Cube 设计目标是面向 allow querying them with SQL 的数据源;
- 不适合直接抓 REST / GraphQL / 其他 API。
这意味着 Cube 最适合接入:
- Snowflake
- BigQuery
- Databricks
- Redshift
- ClickHouse
- Postgres
- MySQL
- Trino / Presto
- Athena
- Doris / StarRocks 等 SQL/OLAP 引擎
如果你的底层只有业务 API,一般需要:
- 先把数据同步到 SQL 数据源;或
- 自己实现 custom data source driver。
2. 语义模型层:Cube 的真正核心
官方文档中,Cube 把 data model 描述为:
- 把 raw data 转换为有意义的 business definitions;
- 并通过 rich set of APIs 暴露给下游;
- 同时支持 pre-aggregate data 以获得更好的查询结果。
可以将其理解为:
“把业务定义编译进代码,而不是散落在 SQL、BI 工具、口头约定和 Prompt 里。”
语义模型通常定义在 YAML 或 JavaScript 中,内容包括:
- cubes
- views
- measures
- dimensions
- segments
- joins
- pre-aggregations
- access policies
3. API Instances:处理前台查询
官方部署文档中指出:
- API Instances 负责处理传入请求;
- 可以查询 Cube Store 中的预聚合数据;
- 也可以直接查询底层原始数据源;
- 支持水平扩展与负载均衡。
因此,在生产环境中,API Instances 更接近“语义查询入口层”。
它们主要做什么
- 接收 REST / GraphQL / SQL 请求;
- 解析请求中的 measures / dimensions / filters / time dimensions;
- 查找对应 cube / view;
- 计算 join path;
- 判断缓存或预聚合是否可命中;
- 编译底层查询;
- 返回结构化结果。
4. Refresh Worker:处理后台刷新
部署文档里,Refresh Worker 的角色也非常清晰:
- 更新 pre-aggregations;
- 让 refresh keys 保持最新;
- 在后台失效 in-memory cache;
- 预聚合是主动构建和维护的,而内存缓存是惰性填充的。
可以进一步概括为:
- API Instance = 前台查数
- Refresh Worker = 后台保鲜
这也是为什么生产环境里,查询与刷新应当解耦。
5. Cube Store:预聚合存储与查询引擎
文档中把 Cube Store 定义为:
purpose-built pre-aggregations storage for Cube
也就是说,它不是通用数据库,而是专门为 Cube 的预聚合场景设计的。
其基本结构
部署文档说明,Cube Store 采用分布式查询引擎架构:
- Router:负责连接、元数据、查询规划和调度;
- Workers:负责摄取已预热的数据并并行执行查询;
- Blob Storage:保存列式格式的预聚合数据。
为什么它重要
因为语义层如果只有“编译查询”,但没有自己的高性能预聚合存储层,那么在高并发、高频率探索分析时,仍然会过度依赖上游数仓。
Cube Store 的存在,让 Cube 从“分析 API 框架”升级成“语义层 + 查询加速层”。
6. 两级缓存体系
Cube 的缓存体系可分为两层:
第一层:in-memory cache
- 默认开启;
- 对重复请求起缓冲作用;
- 可视为“短期结果缓存”。
第二层:pre-aggregations
- 需要显式定义;
- 本质上是物化后的聚合结果;
- 用于真正降低延迟与上游数仓成本。
文档中将 pre-aggregations 描述为 aggregate awareness 的实现方式:
- Cube 可以分析查询;
- 从已定义的 pre-aggregation 规则中匹配最优结果;
- 如果可用,则直接查询预聚合而不是原始数据。
7. API 层:给谁用,怎么用
Cube 的 API 层不是“单一接口”,而是一组面向不同消费方式的接口。
REST API
适合:
- 前端应用
- 嵌入式分析
- 自动任务
- 一些低代码或 Notebook 场景
GraphQL API
适合:
- GraphQL 风格前端
- 需要类型化查询结构的应用
SQL API
适合:
- BI 工具
- SQL 客户端
- Notebook
- 喜欢“像查数据库一样查语义层”的数据消费者
MCP / AI 接入
更适合在“AI 助手接语义层”的场景中使用,属于更上层的集成方式。
8. 从官方代码仓库看整体结构
核对上游仓库(2026-05-22)后,可以看到 Cube 的官方代码库中至少有几类关键目录:
packages/
包含大量 Node/TypeScript 侧组件,例如:
cubejs-server-corecubejs-schema-compilercubejs-query-orchestrator- 各类
cubejs-*-driver - 各类前端 / SDK 包
这说明 Cube 并非单一服务,而是一整套语义层运行时、驱动、客户端与工具链。
rust/
包括:
rust/cubestorerust/cubesql- 其他 Rust 子模块
这与官方文档、博客中对 Cube Store / SQL 引擎 Rust 化的叙述一致。
examples/recipes/
仓库中有大量 recipes,例如:
- active users
- role-based access
- column-based access
- mandatory filters
- multiple data sources
- non-additivity
- refreshing select partitions
这意味着在编写中文教程时,可以将官方 recipes 作为重要的实战补充材料。
9. 你应该如何向中文读者解释这个架构
推荐使用下面这个表述:
Cube 不是单纯把自然语言转成 SQL 的工具,而是站在数据源与数据消费端之间的一层“可编排、可治理、可缓存、可 API 化”的统一业务语义层。
这个表述比“指标平台”更全面,比“BI 后端”更准确,也比“Text2SQL 工具”更接近实际。
一句话总结
Cube 的核心架构由语义模型、API Instances、Refresh Worker、Cube Store 与多种查询接口组成;它的本质是把业务语义编译成可执行分析接口,并用缓存和预聚合保证性能。