精读:Semantic Layer and AI: The Future of Data Querying with Natural Language
- 原文:Semantic Layer and AI: The Future of Data Querying with Natural Language
- 作者:Simon Späti
- 发布时间:2024-12-19
- 原文链接:https://cube.dev/blog/semantic-layer-and-ai-the-future-of-data-querying-with-natural-language

这篇为什么值得读
这篇文章更接近一篇“架构综述”:它将自然语言问数背后的组件逐一拆开,而不是只强调结果界面。对于中文读者而言,它尤其适合回答两个问题:
- 为什么 semantic layer 是 GenAI 的好起点?
- 一个真正可用的自然语言问数系统究竟包含哪些中间层?
自然语言问数架构图
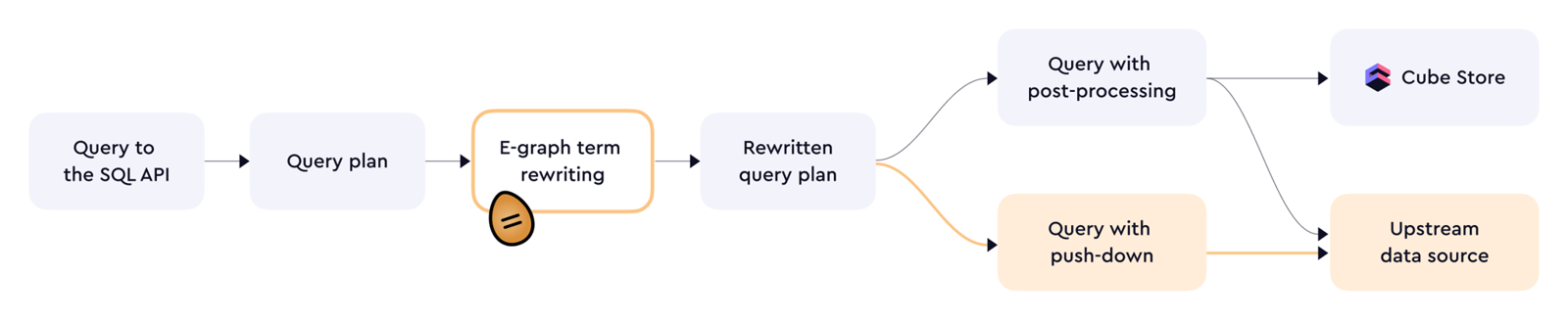
核心观点
1. Semantic layer 是自然语言查询的理想基础层
原文的主判断是:semantic layer 提供了从数据源到业务需求之间的结构化桥梁。原因包括:
- declarative metrics definitions
- comprehensive data models
- metadata management
换成更容易理解的话说:
模型不是直接面对表,而是面对已经整理好的业务语义。
2. 自然语言查询并不是“Prompt 一下就完了”
文章明确指出,从指令到答案之间,有很多中间环节:
- prompt augmentation
- schema / metadata retrieval
- SQL query generation
- response generation
这能帮助中文读者修正一个常见误区:
自然语言问数不是一个模型能力点,而是一条系统链路。
3. Semantic layer 在这条链路里扮演 deterministic compiler 的角色
文章中一个非常关键的说法,是 Cube API 会把 prompt 相关请求以更确定性的方式编译成 SQL。
也就是说,LLM 负责理解问题,但真正把问题落到结构化执行层的,是语义层和中间 API。
4. 典型 AI 问数架构不只包含 LLM
原文列出了几个关键组件:
- semantic layer
- LLM / response generation
- RAG
- semantic catalog
- API and SQL transpiler
这很有启发性,因为很多团队会把所有复杂度都压给 LLM,但文章强调的是 系统分层。
5. 这篇文章带有明显的产品阶段背景
原文开头有一句提示:当时的 AI Assistant 已演进到 Cube D3。说明这篇文章一部分内容带有 2024 年末到 2025 年产品演进背景。
因此读它时要把两部分分开:
- 长期有效的方法论:semantic layer + AI 的架构关系;
- 阶段性产品叙述:当时具体的品牌与产品形态。
和本教程哪几章最相关
对中国团队的启发
1. 做智能问数时,要优先拆组件而不是堆大模型
你需要的通常不是“更大模型”,而是先补齐:
- 语义建模
- metadata retrieval
- query compilation
- access control
- result explanation
2. 自然语言问数的最小闭环不是聊天,而是可追踪的执行链路
如果没有中间 API 和语义层编译环节,你很难回答:
- 为什么这个答案是这么算出来的?
- 这次命中了哪个指标定义?
- 这个 join path 为什么合法?
3. Semantic catalog 也值得作为后续扩展方向
如果后续继续扩展中文教程,可以单独撰写一篇:
- 如何让 Agent 先理解语义资产,再发起查询。
我的补充判断
这篇文章的重要价值在于提醒我们:
自然语言查询真正的难点不在“把中文翻译成 SQL”,而在“如何让整个过程在业务语义、执行约束与结果解释上都保持确定性”。
Cube 在这里承担的角色,更接近 deterministic middle layer,而非单纯的数据源连接器。
一句话总结
这篇文章尤其适合用于解释“自然语言问数的系统架构”:semantic layer 让 AI 问数从一个不稳定的 Prompt 技巧,变成一条可编译、可治理、可解释的执行链路。