生产部署:API Instances、Refresh Worker、Cube Store 应该怎么搭
从开发环境进入生产时,Cube 的部署模型要发生一次明显升级。
生产组件分层图
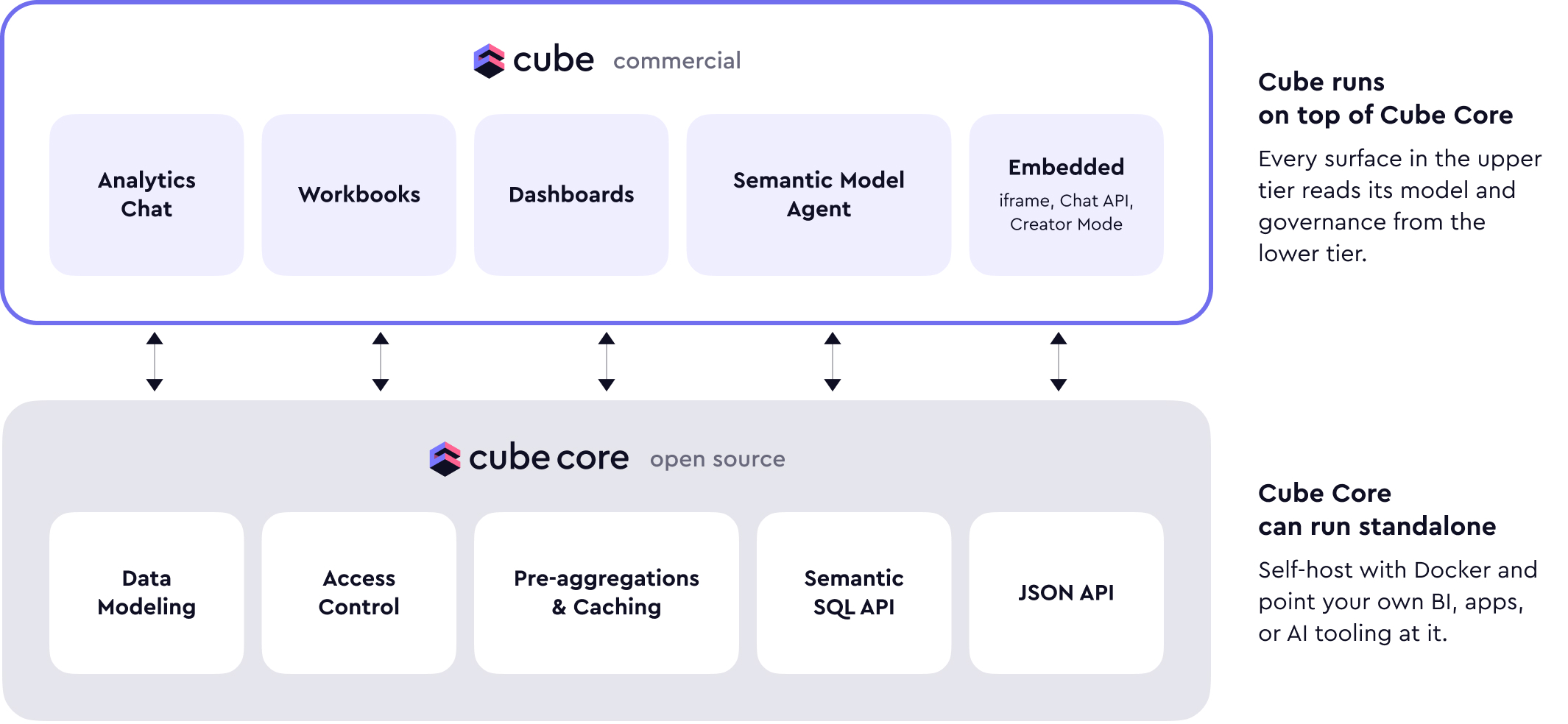
1. 官方生产组件模型
Cube 部署文档给出的典型生产组件包括:
- 一个或多个 API Instances
- 一个 Refresh Worker
- 一个 Cube Store cluster
这已经足够构成对生产环境的基本认知。
2. 为什么开发模式不能直接等于生产模式
开发模式的目标是:
- 快速修改模型;
- 快速调试查询;
- 本地验证结果。
生产模式的目标则是:
- 稳定服务并发请求;
- 独立处理刷新任务;
- 保持缓存与预聚合最新;
- 支撑更高吞吐量与更低延迟。
所以生产环境一定要把“前台查数”和“后台刷新”拆开。
3. API Instances:线上查询入口
API Instances 负责:
- 接收来自 BI、应用、Agent 的请求;
- 查询 Cube Store 或直接查询原始数据源;
- 水平扩展以支撑更高 QPS。
生产建议
- 放在负载均衡后面;
- 至少准备两实例以避免单点;
- 让每个实例都能访问相同的数据模型文件。
4. Refresh Worker:线上保鲜机制
Refresh Worker 负责:
- 构建和刷新 pre-aggregations;
- 更新 refresh keys;
- 后台失效内存缓存。
生产建议
- 单独部署,不要和 API 实例绑死在一起;
- 视预聚合规模调高并发或扩成多集群;
- 多租户很多时要关注刷新压力。
官方刷新文档也提到,如果租户很多、预聚合很多,可能需要多集群拆分刷新压力。
5. Cube Store:别把它看成可选边缘件
只要你的场景满足以下任一条件,就应该认真考虑 Cube Store:
- 并发高;
- 查询频繁;
- 数据量大;
- 追求亚秒级体验;
- 想显著降低上游数仓成本。
结构回顾
- Router:接收查询、做元数据管理与计划分发;
- Workers:并行执行子查询;
- Blob Storage:存放列式预聚合数据。
官方建议
部署文档明确表示:
- Cube Store 虽可单实例运行;
- 但这通常 不适合生产;
- 对高并发和高吞吐,建议使用集群方式。
与性能相关的结构图
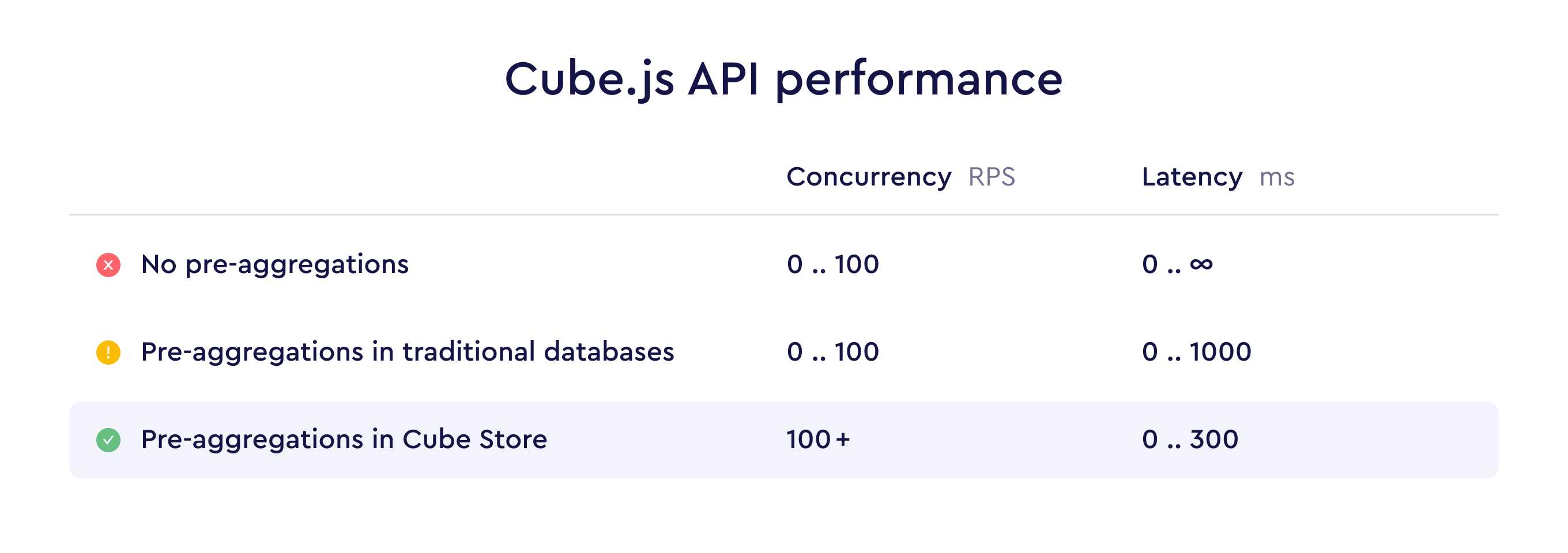
6. 生产环境中最容易忽略的问题
1)模型文件如何分发
所有 API Instances 与 Refresh Worker 都需要访问语义模型文件。
2)预聚合存储位置
如果你使用 Cube Store,通常还要设计对象存储或相应存储后端。
3)监控
至少要关注:
- 查询延迟;
- 预聚合构建时长;
- 刷新失败率;
- Worker 压力;
- 命中率与回源比例。
4)发布流程
语义模型本身是代码资产,应该进入:
- Git
- Code Review
- CI/CD
- 环境发布流程
7. 一个适合中文教程的部署分层方式
阶段 1:本地 PoC
- 单实例 Cube
- 单数据源
- 无 Cube Store 或最简单模式
阶段 2:团队内试点
- 多 API Instances
- 独立 Refresh Worker
- 开始使用 pre-aggregations
阶段 3:正式生产
- Cube Store cluster
- 对象存储
- 完整监控
- 多环境 / 多租户治理
- 灰度发布与回滚策略
8. 什么情况下应该考虑多集群
官方文档在多租户与部署章节里都提示:
- 大规模多租户;
- 超过 100 租户量级;
- 刷新负载很重;
- 预聚合很多;
都可能需要多集群架构,而不是一套单集群打天下。
9. 教程落地建议
如果后续继续扩展这套中文教程,可考虑新增三篇:
- Docker Compose 最小生产部署;
- Cube Store 集群与对象存储;
- 多租户生产部署模式。
一句话总结
Cube 的生产部署核心在于把查询入口、后台刷新和预聚合存储拆分成可独立扩展的组件:API Instances 负责前台请求,Refresh Worker 负责保鲜,Cube Store 负责高性能预聚合查询。