查询 API:REST、GraphQL、SQL 应该怎么选
Cube 的一个核心优势,就是用多种标准接口暴露同一套语义层。
SQL API / BI 集成示意图

1. 官方 API 主线是什么
Cube 文档中的 Core Data APIs 主线包括:
- SQL
- REST
- GraphQL
- DAX
同时文档也明确写到:
- 连接 AI assistants 可以使用 MCP server;
- 做 embedded analytics 与 real-time analytics,优先考虑 REST / GraphQL;
- 做 BI / self-serve BI,可优先考虑 SQL API 或更高层同步方案。
对于 Cube Core 中文教程而言,最重要的接口包括:
- REST API
- GraphQL API
- SQL API
2. REST API:最通用的应用查询方式
官方文档中,REST API 被描述为适合:
- front-end applications
- data notebooks
- low-code tools
- automated jobs
最常用端点
/cubejs-api/v1/load:执行语义查询/cubejs-api/v1/meta:查看当前语义模型/cubejs-api/v1/cubesql:通过 HTTP 提交 SQL API 查询
一个最小查询
bash
curl -H "Authorization: TOKEN" -G --data-urlencode 'query={"measures":["orders.count"]}' http://localhost:4000/cubejs-api/v1/load什么时候最适合选 REST
- 你在写前端应用;
- 你希望请求结构天然就是 JSON;
- 你要与嵌入式分析、自动任务、Node/JS SDK 对接。
3. GraphQL API:适合 GraphQL 生态前端
GraphQL API 文档指出,它通过 /graphql 暴露,常用于 GraphQL-enabled data applications。
查询示例
graphql
{
cube {
orders {
count
status
created_at {
day
}
}
}
}优点
- 更贴合 GraphQL 前端;
- 对类型化前端更友好;
- 查询结构清晰。
注意点
官方文档也列出了一些限制,例如:
- 不支持 WebSocket transport;
- 不支持 segments;
- 不支持元数据查询;
- 不支持 compare date range 等部分 REST 功能。
因此,GraphQL 很好,但不一定适合作为“最全功能入口”。
4. SQL API:把语义层当数据库使用
SQL API 是 Cube 非常有代表性的能力。
文档中明确写道:
- SQL API 通过 Postgres-compatible protocol 提供数据;
- 一般只要能连 PostgreSQL 的工具,就有机会连接 Cube;
- 在 SQL API 中,每个 cube 或 view 都会映射成一张表;
- measures、dimensions、segments 会映射成这些表中的列。
查询示例
sql
SELECT
users.state,
orders.status,
MEASURE(orders.count)
FROM orders
CROSS JOIN users
WHERE orders.created_at BETWEEN '2020-01-01' AND '2021-01-01'
GROUP BY 1, 2
LIMIT 10;什么时候最适合选 SQL API
- 你要接 BI 工具;
- 你要给 Notebook 用户提供统一语义查询入口;
- 你希望用户像查数据库一样查语义层。
Query Pushdown 示意图
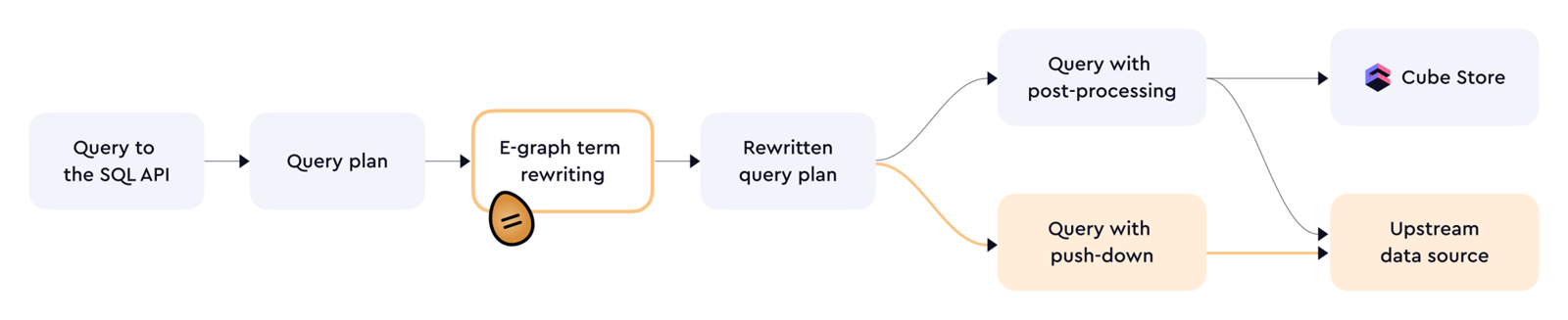
5. /v1/meta 为什么特别重要
REST API 文档明确提到:
- 可以通过
/v1/metaintrospect data model。
这对 AI 与工具集成很关键,因为很多上层系统都需要先知道:
- 有哪些 cubes / views;
- 有哪些 measures / dimensions;
- 每个成员类型是什么;
- 哪些字段适合用户选择。
换句话说,/v1/meta 是“让消费端理解语义层结构”的关键接口之一。
6. 给中文读者的选择建议
如果你做前端 / embedded analytics
优先选 REST API。
如果你已经是 GraphQL 技术栈
可以选 GraphQL API。
如果你做 BI / Notebook / 数据平台接入
优先考虑 SQL API。
如果你做 AI 助手对接
语义查询主线仍然是 REST / SQL / GraphQL; 如果要接 MCP 生态客户端,再补 MCP 这一层。
7. 为什么多 API 是 Cube 的重要优势
因为 headless semantic layer 的核心价值就在于:
同一语义模型,应当能被多个异构消费端复用。
如果语义层只能服务某一个前端,它更接近内置语义模型; 只有当它能够同时服务 BI、App、Dashboard、Notebook 与 AI 时,headless 的价值才会充分体现。
一句话总结
REST 适合应用,GraphQL 适合 GraphQL 前端,SQL 适合 BI 和 Notebook;三者共享同一套 Cube 语义模型,这正是 Cube 作为 headless semantic layer 的关键价值。