精读:The Need for an Open Standard for the Semantic Layer
- 原文:The Need for an Open Standard for the Semantic Layer
- 作者:Artyom Keydunov、Brian Bickell
- 发布时间:2023-10-19
- 原文链接:https://cube.dev/blog/the-need-for-an-open-standard-for-the-semantic-layer

这篇为什么值得读
这篇文章不直接讨论某个具体功能,而是关注一个更长期的问题:
语义层会不会像数据库、容器、身份认证一样,逐渐需要开放标准?
如果你关注生态、互操作性、供应商锁定与长期架构,这篇文章值得认真阅读。
对象标准化示意图
核心观点
1. 语义层的承诺是“一致性”
文章先强调了 semantic layer 的承诺:
- 不同数据工具看到的是同一套 metrics;
- access control 一致;
- performance characteristics 尽量一致;
- 用户体验又要安全又要快。
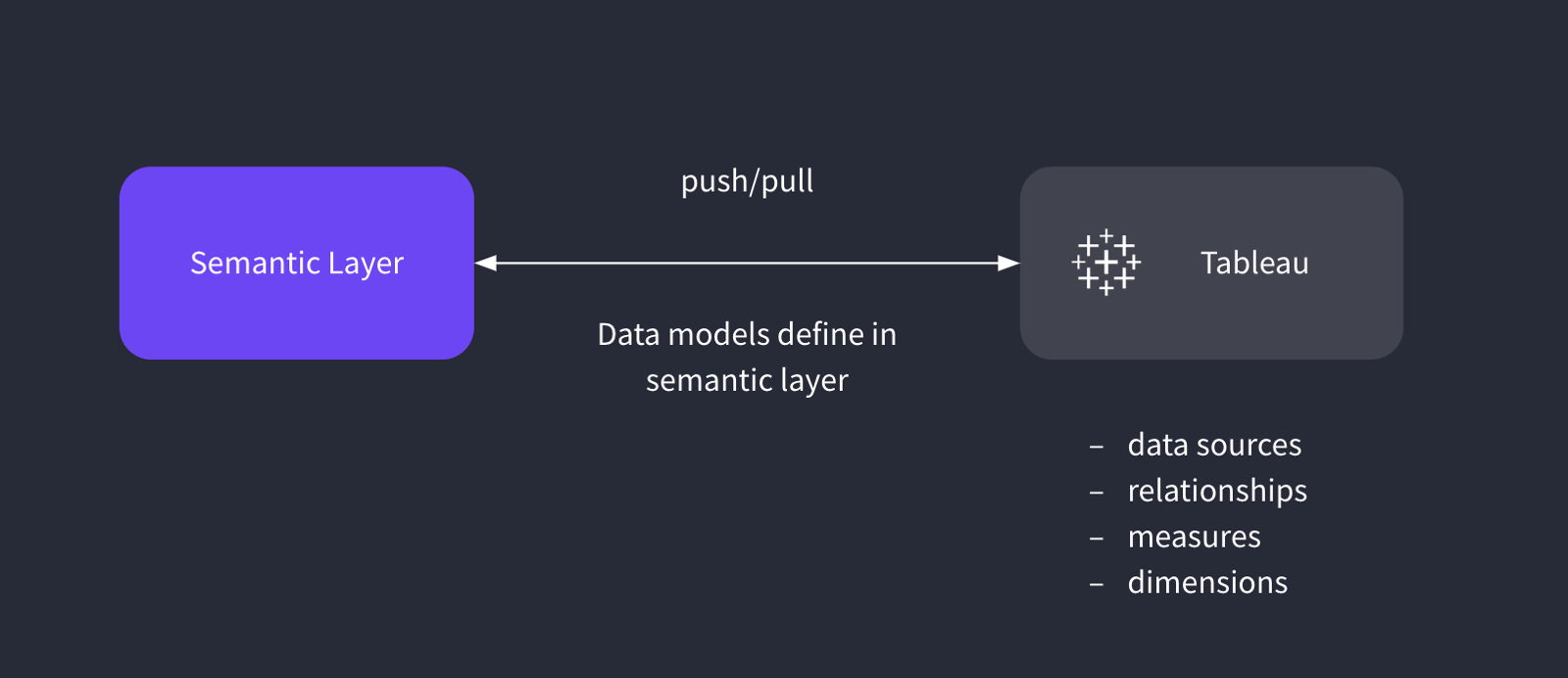
这意味着语义层天然是一个跨工具、跨消费端的中间层。
2. 如果没有标准,语义层价值会被生态碎片化削弱
原文指出,一个语义层即使功能很强,如果很难与周边数据栈集成,价值也会受限。
这背后的问题是:
- BI 工具很多;
- Notebook 很多;
- embedded analytics 形态很多;
- 新的数据应用还在不断出现。
没有共同标准,每新增一个工具,集成成本都会重复发生。
3. 文章提出开放标准应覆盖三大方面
原文给出三个主要方向:
- Specification of Objects
- Querying Protocols
- Metadata Exchange Protocols
这是很有启发性的,因为它把“标准”拆成了:
- 对象怎么表示;
- 怎么查询;
- 怎么交换元数据。
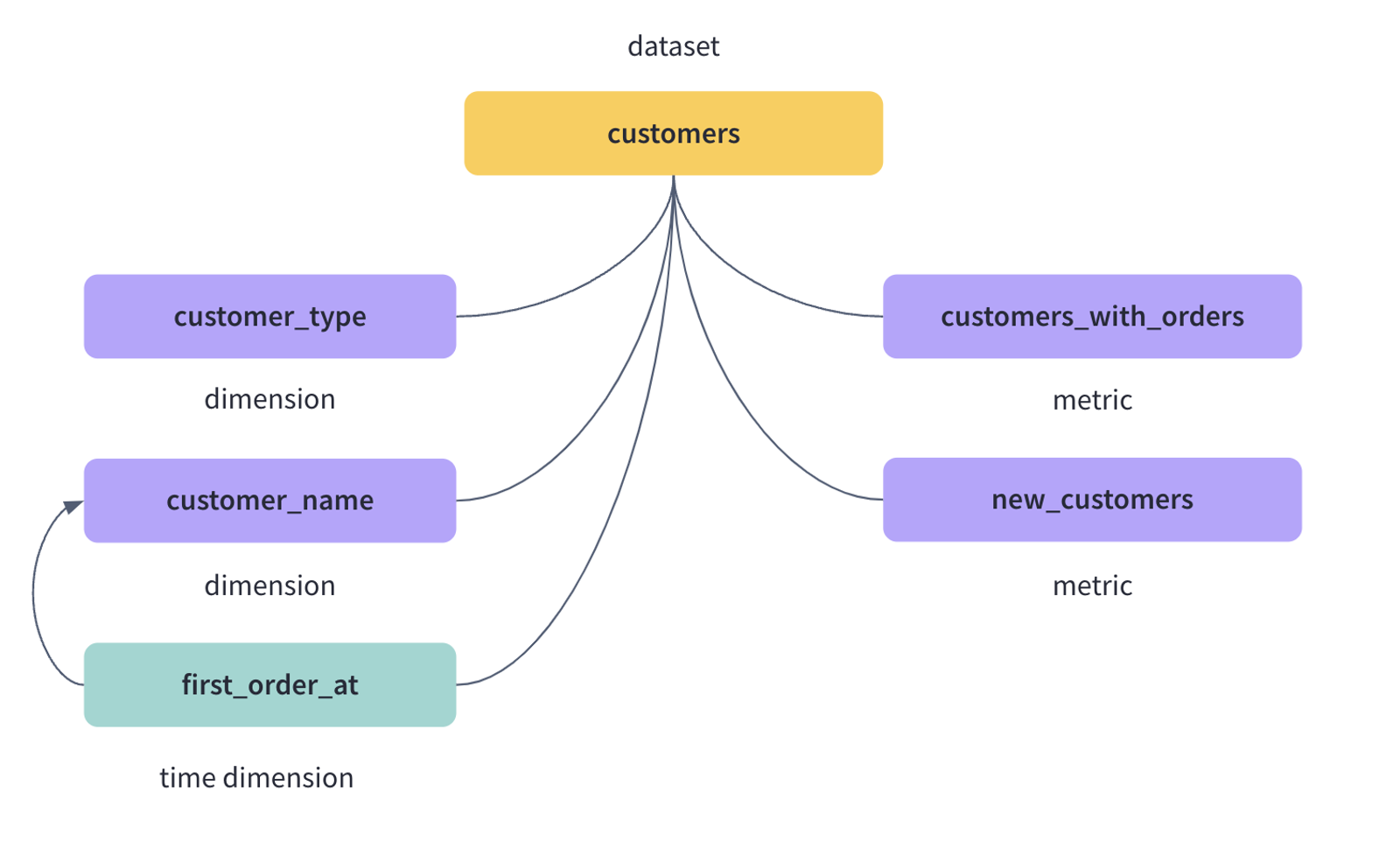
4. Cube 更偏 dataset-centric 的 outward representation
文章讨论了两类思路:
- metrics-centric
- dataset-centric
并说明 Cube 更倾向 dataset-centric,因为现有数据工具大多还是以表格、数据集为中心。
这个判断和 Cube 的 views / SQL API / 多工具兼容路线是吻合的。
5. 开放标准的意义不仅是技术,还包括降低锁定与切换成本
原文明确指出,标准会降低:
- 供应商接入负担;
- 用户切换成本;
- 单厂商绑定带来的风险。
这对企业客户来说,是很现实的价值。
互操作视角示意图
和本教程哪几章最相关
对中国团队的启发
1. 语义层选型不能只看功能,还要看开放性
长期来看,更关键的问题是:
- 能不能被多个工具复用;
- 模型和 metadata 能否稳定暴露;
- 是否容易接 BI、AI、应用前端、电子表格。
2. view 的价值并不只在于让用户“看起来更简单”
文章里谈到 entity-first / metric-first outward representation,这能帮助我们更好地理解:
- view 是语义层对外呈现方式的重要工具;
- 不同消费端可以看到不同形态的数据产品。
3. AI 时代会让标准化更重要
因为 AI 工具链和客户端正在迅速增多,标准化 metadata / query protocols 的价值会进一步提升。
我的补充判断
这篇文章的重要意义不在于说明 Cube 已经定义了标准,而在于指出了一个趋势:
只要语义层真成为“数据消费的统一入口”,那么标准化迟早会成为生态必答题。
今天看,这个判断仍然成立,而且在 AI 接入越来越多之后,重要性只会继续上升。
一句话总结
这篇文章最值得记住的是:语义层若想真正成为跨工具基础设施,就必须逐步走向对象表示、查询协议与元数据交换的开放标准化。