Blog 专题:产品定位、嵌入式分析与开放标准

本专题更偏向“为什么”与“长期方向”,适合作为路线理解与技术选型参考。
推荐阅读卡片

The Future of Cube Core and Cube
帮助区分开源底座与完整平台,并理解 agentic analytics 的方向。

The Modern Data Stack for Embedded Analytics
说明 Cube 的 headless 设计为什么天然适合多前端和嵌入式分析。
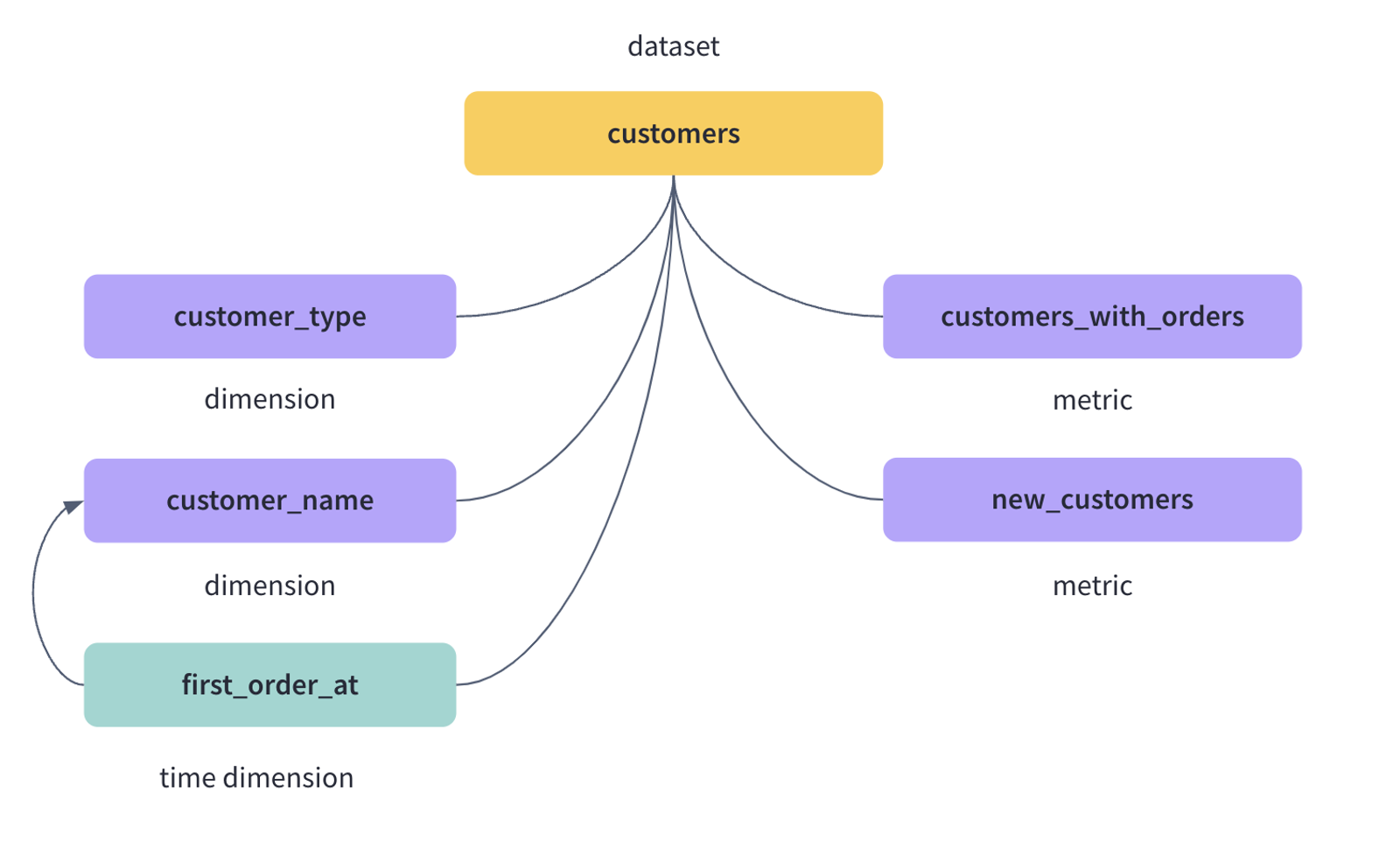
Where should a semantic layer be built?
解释 data model 与 semantic layer 是上下游,而不是二选一。
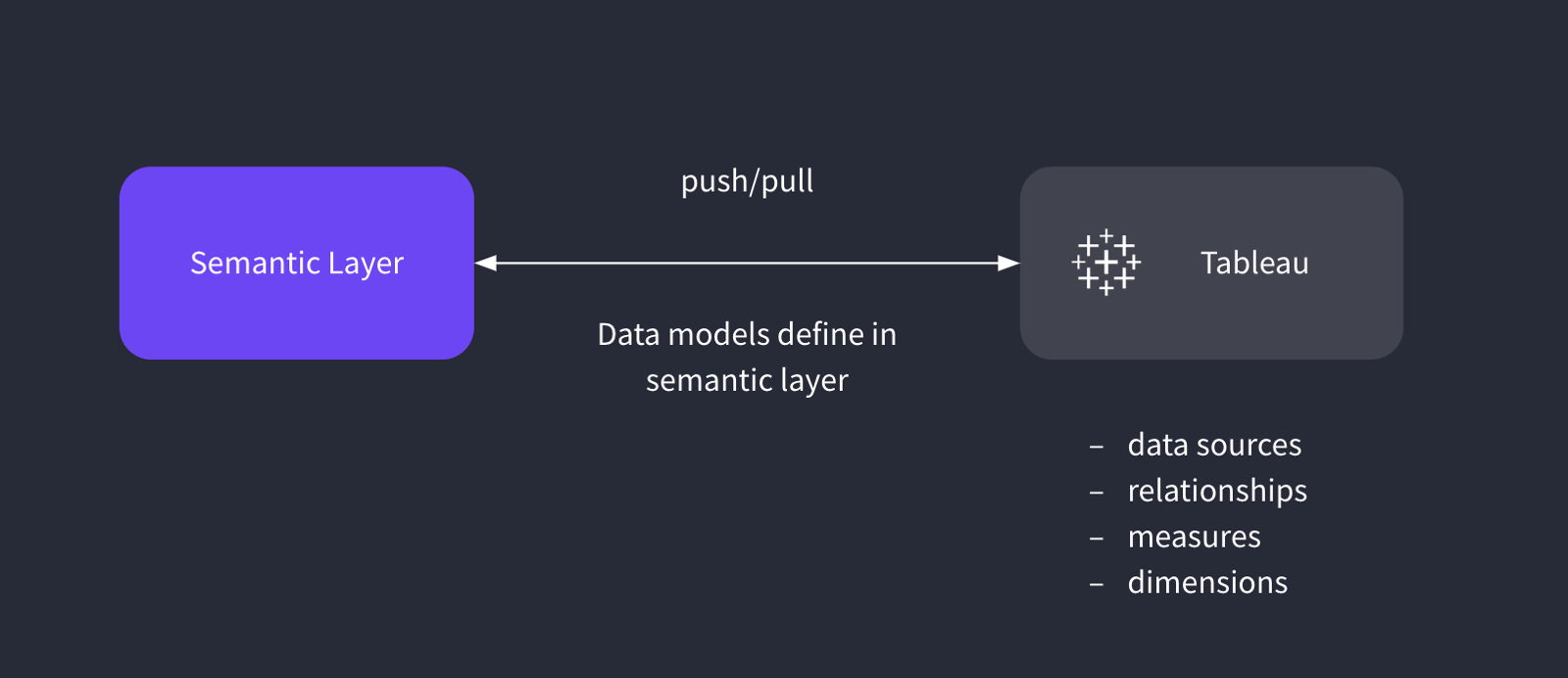
The Need for an Open Standard for the Semantic Layer
讨论语义层能否成为基础设施,最终取决于互操作性与开放标准。
Core / Platform 分层架构图
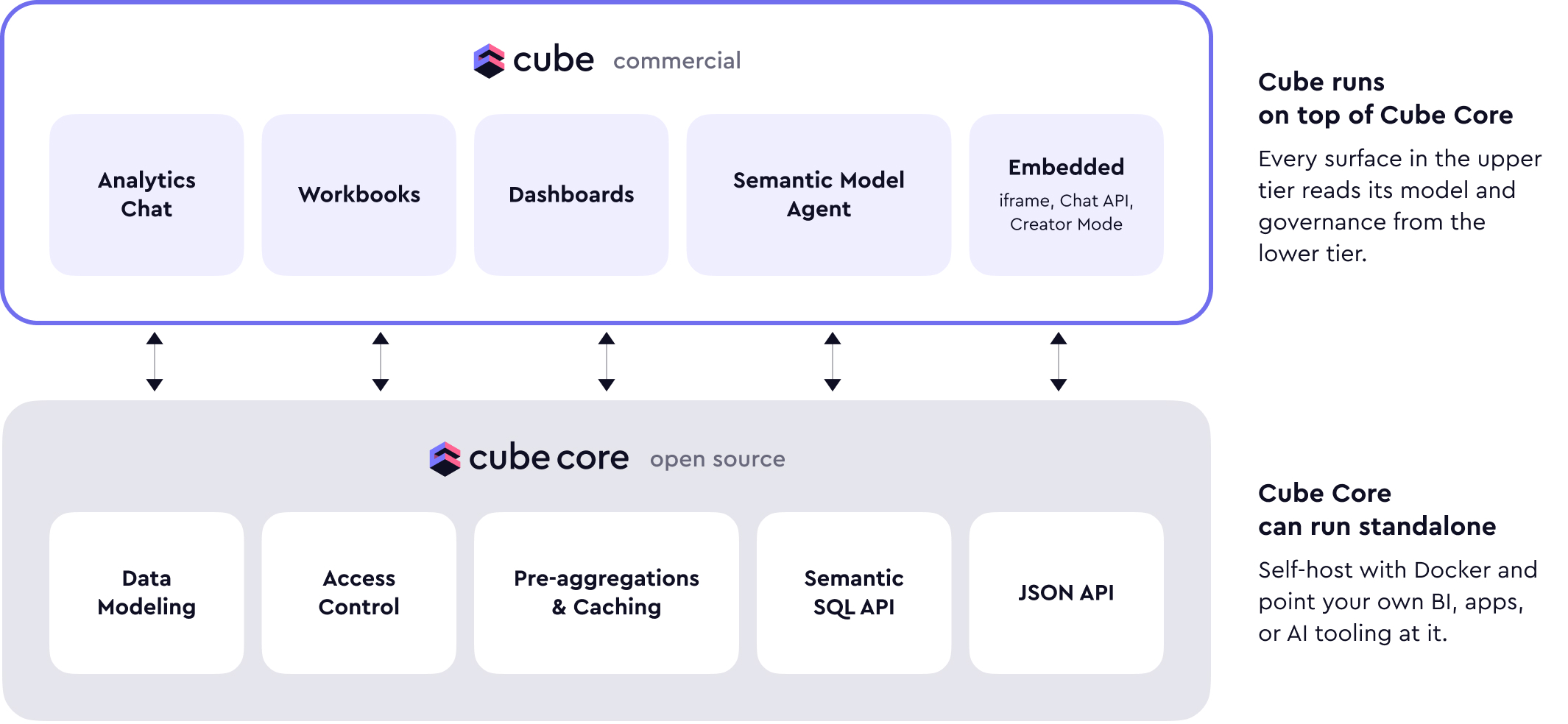
本专题关注的问题
1. Cube Core 与 Cube 平台怎么分工
第一篇尤其关键,用于帮助读者区分:
- 开源语义层底座;
- 完整商业平台;
- 为什么两者都继续存在。
2. 为什么 Cube 从 embedded analytics 长出来
第二篇说明:
- Cube 的 headless 特性不是偶然;
- 它本来就服务“多前端、多租户、定制化分析”场景;
- AI 则是沿同一路线自然延伸的结果。
3. 为什么“已有 data model”不等于“不需要 semantic layer”
第三篇说明:
- data model 解决组织;
- semantic layer 解决消费、治理、接口与性能。
4. 为什么开放标准会越来越重要
第四篇说明:
- 语义层若想成为基础设施,就必须提高互操作性;
- 对象表示、查询协议、元数据交换都会逐渐标准化。
两张与开放标准相关的图
五个关键判断
- Cube 不是纯 BI 前端,也不是纯 AI 工具。
- 它的根在 embedded analytics 和 headless semantic layer。
- data model 与 semantic layer 是上下游,不是二选一。
- 标准化决定语义层能否成为生态基础设施。
- Cube 的很多 AI 优势,其实来自更早的架构选择。
对应本教程主线
一句话总结
本专题的核心结论是:Cube 的产品路线是“从 embedded analytics 的 headless semantic layer,延伸为 AI 时代的统一分析底座”。