精读:Semantic Layers are the missing piece for AI-Enabled Analytics
- 原文:Semantic Layers are the missing piece for AI-Enabled Analytics
- 作者:Brian Bickell、David Jayatillake
- 发布时间:2023-12-05
- 原文链接:https://cube.dev/blog/semantic-layers-the-missing-piece-for-ai-enabled-analytics
这篇为什么值得读
如果上一组文章更偏方法论,这篇文章则进一步回答一个更偏工程的问题:
语义层对于 LLM 分析到底有没有可验证的准确性提升?
文章的价值不在于结论本身,而在于它引入了 benchmark 思维。
核心观点
1. Cube 团队意识到:仅有客户案例,不足以说明问题
原文非常坦诚地说,团队此前更多是 anecdotal evidence,缺少系统性的实证验证。
这一点值得重视。AI 数据产品如果只展示 demo 和故事,很难真正说服工程团队与数据团队。
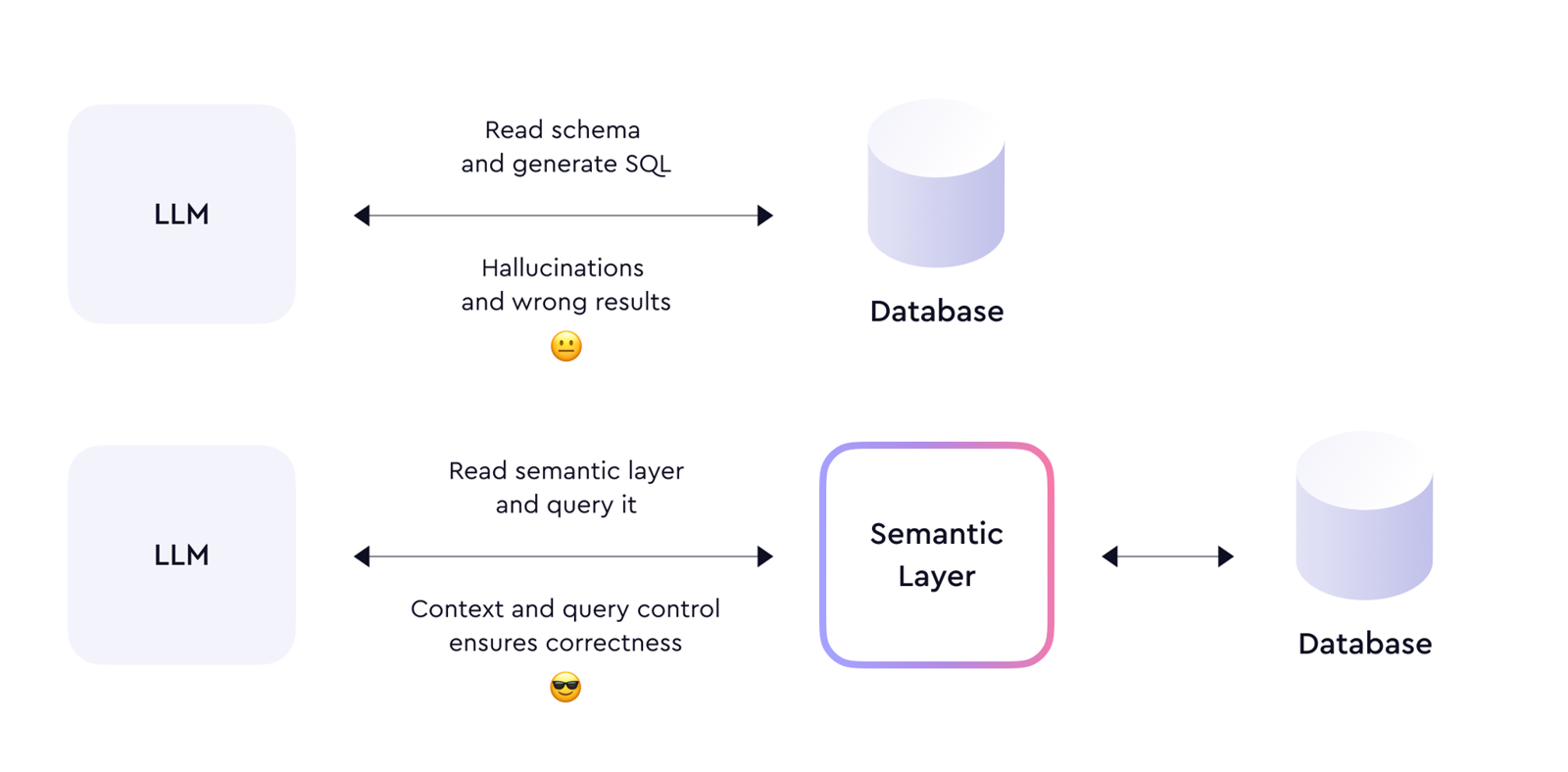
2. 文章把“语义层的价值”压缩成两个词:context 与 constraint
这是整篇文章最值得保留的部分。
- context:帮助 LLM 理解实体、指标、维度和业务关系;
- constraint:限制它只能按特定结构形成请求,而不是任意发挥。
很多团队现在只做前者,比如多塞一些 schema、文档、表说明; 但 Cube 强调的是:没有约束的上下文仍然不够。
3. REST API 这种强结构化接口,对 LLM 很友好
文章指出,Cube 的请求形式天然接近自然语言里的“指标、维度、过滤条件列表”,同时格式又高度受限。
这带来的好处是:
- 生成错了更容易报错;
- 比起放任模型生成任意 SQL,更少出现“看似合理但语义错”的幻觉。
4. 文章引用了外部 benchmark 方法,并在此基础上复现实验
原文提到:
- 借鉴了 data.world 的研究方法;
- 参考了 dbt Labs 的测试思路;
- 用 Delphi + Cube 做了复现实验。
这说明 Cube 团队开始尝试把“语义层 + LLM”的讨论拉向更可比较的工程实验。
5. 文章给出的结论是:语义层对准确性有显著帮助
文中展示的结果是 Delphi + Cube 在其复现实验中取得了很强的表现。
这里需要做一个审慎解读:
- 这说明 semantic layer 方向是对的;
- 但它不等于所有问题都被解决;
- benchmark 结果也仍然依赖任务集、建模质量、prompt 与系统设计。
因此最稳妥的结论不是“有了语义层就 100%”,而是:
语义层显著提高了让 LLM 走向可靠分析系统的概率。
和本教程哪几章最相关
对中国团队的启发
1. 做 AI analytics 不要只做 demo,要做 benchmark
至少应测试:
- 指标匹配正确率
- join path 正确率
- 时间粒度理解正确率
- 权限边界
- 多轮追问一致性
2. “结构化接口”比“自由生成 SQL”更适合多数企业场景
如果目标是可靠性而非演示效果,让模型优先输出结构化 query object 往往更稳妥。
3. 评估时要分开看 context 与 constraint
不少团队把 schema 文档塞给模型后,效果略有提升,就认为问题解决了。 但这篇文章提醒我们:
- 只有 context,不够;
- 只有 constraint,也不够;
- 两者结合才接近可用系统。
我的补充判断
这篇文章在中文技术社区的重要意义,在于它把“语义层对 AI 有帮助”从一句抽象判断,转化为一个可以被实验验证的工程假设。
这会让你的教程从“理念推广”更进一步,走向“系统设计与评测方法”。
一句话总结
这篇文章最值得记住的是:语义层对 LLM 分析的价值,不只是提供上下文,更是同时提供约束;context + constraint 才是可靠 AI analytics 的关键组合。