精读:Semantic Layer: The Backbone of AI-powered Data Experiences
- 原文:Semantic Layer: The Backbone of AI-powered Data Experiences
- 作者:Artyom Keydunov
- 发布时间:2023-06-22
- 原文链接:https://cube.dev/blog/semantic-layer-the-backbone-of-ai-powered-data-experiences

这篇为什么值得读
这是 Cube 关于“语义层为什么是 AI 数据体验底座”的早期代表文之一。它的重要性在于:
- 很早就把 LLM 与 semantic layer 的关系说清了;
- 不仅讨论“补充上下文”,也强调“通过语义层约束查询”;
- 明确把性能和安全也纳入 AI 架构讨论。
关键对比图
核心观点
1. AI 数据体验的爆发,要求底层数据接口升级
原文先从一个更大的背景出发:前端技术进步让数据体验越来越多样,而 LLM 又把数据消费推到新的阶段,从 chatbot 到 agent 都会成为数据消费者。
也就是说,AI 不是新增一个“问答框”,而是在重塑整层数据消费界面。
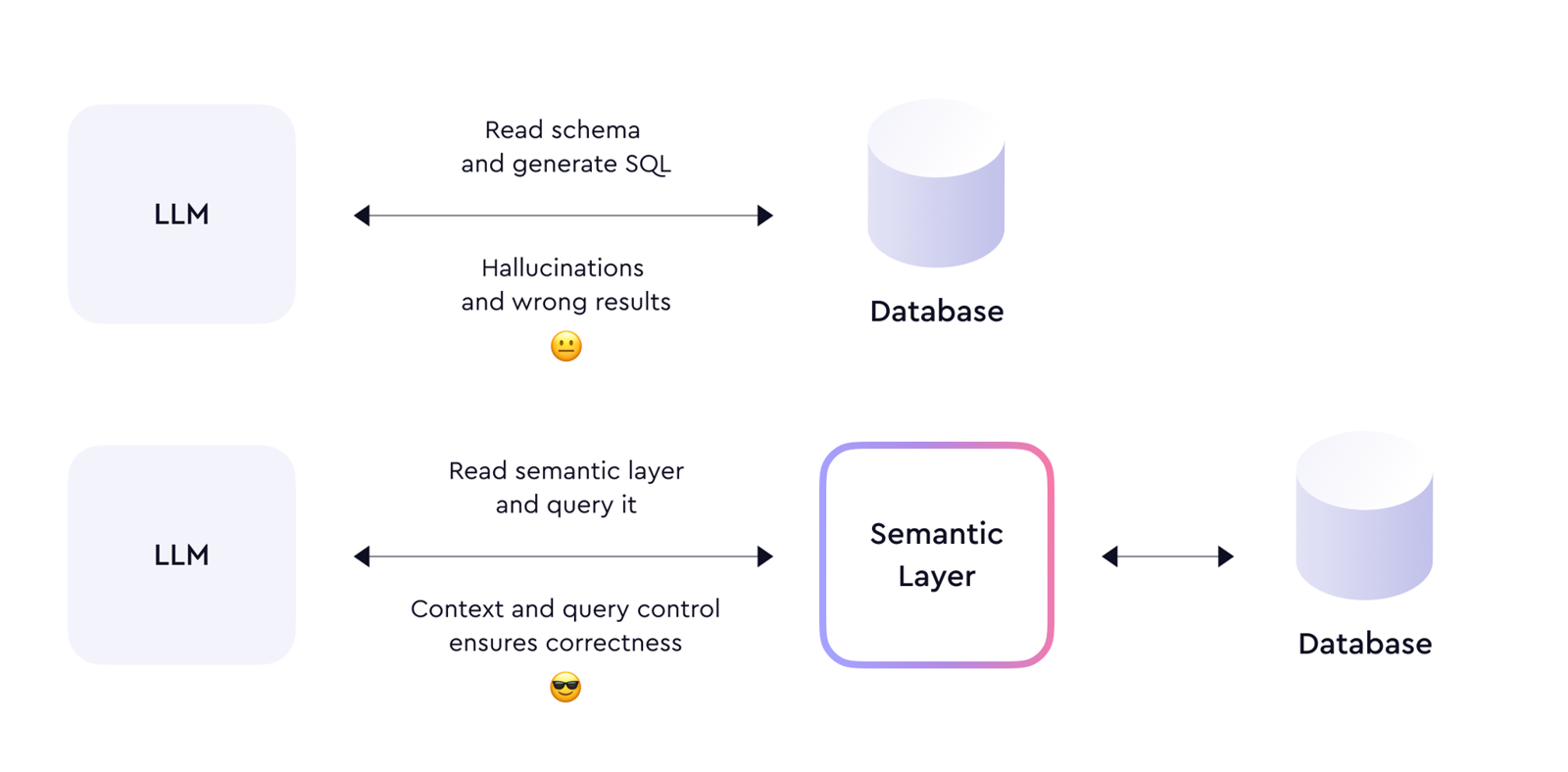
2. 仅把数据库 schema 喂给 LLM 远远不够
文章最核心的判断是:
- LLM 会 hallucinate;
- 数据本身如果混乱,LLM 只会放大混乱;
- 仅有表结构,模型无法正确理解业务指标、实体关系和权限边界。
因此,LLM 需要的不是裸 schema,而是 semantic context。
3. 语义层不仅负责定义,也应成为查询入口
原文强调“querying application is equally important”。
我的理解是:
- 如果语义层只是文档或元数据目录,LLM 依然可能绕开它直写 SQL;
- 只有当查询必须通过语义层发起时,治理与 correctness 才能真正落地。
这点对 AI 方案设计尤其重要。
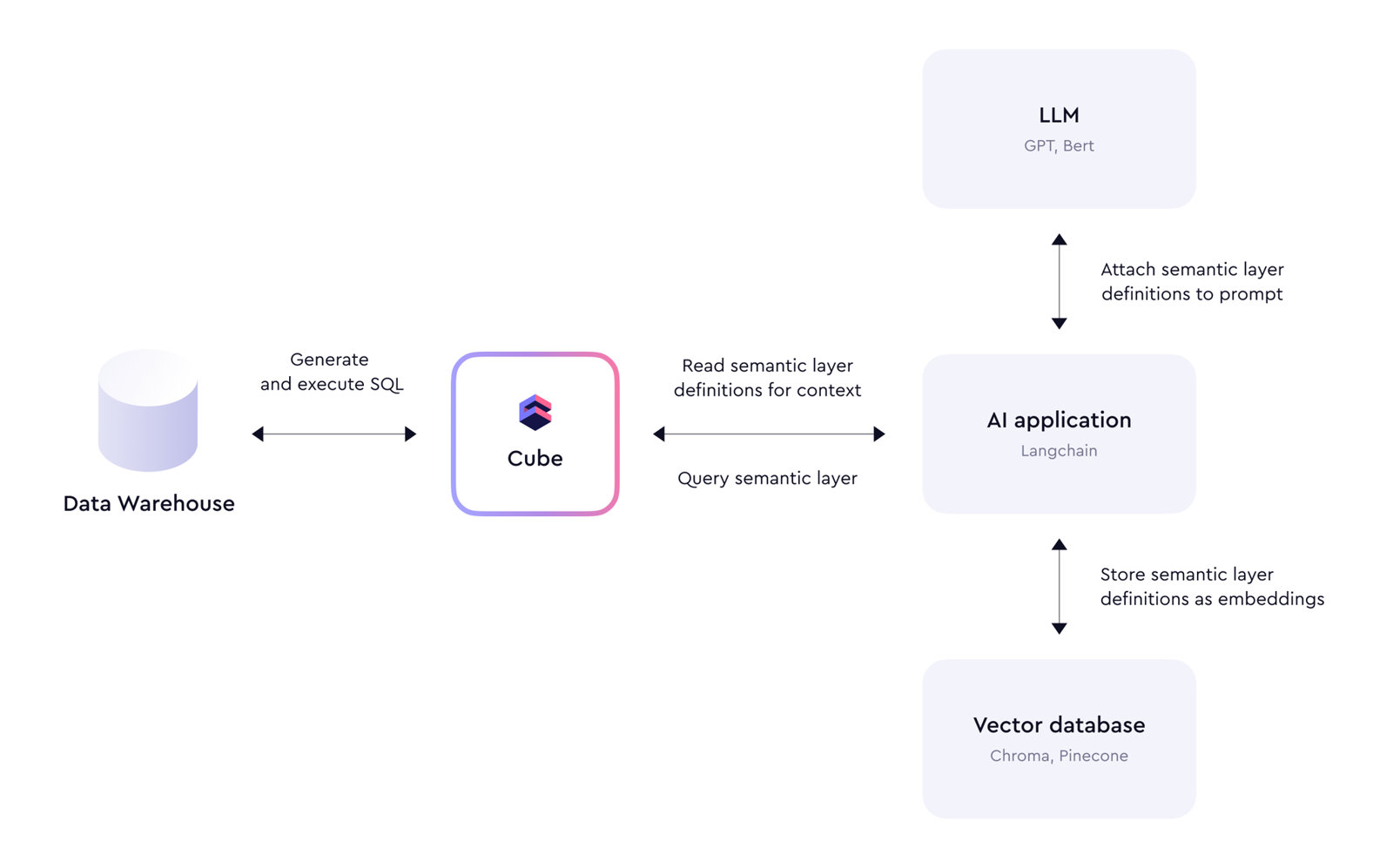
4. Meta API + embedding + retrieval 是很自然的接法
文章举了一个很实用的模式:
- AI 应用先读取 Cube 的 meta API;
- 把语义定义存入向量库;
- 用户发问时,把相关语义上下文补到 prompt;
- 再让模型生成对 Cube 的查询。
这个设计今天看仍然非常实用,尤其适合:
- 智能问数
- 内部数据 Copilot
- 业务域 AI 助手
5. 性能与安全不能在 AI 场景里被降级
文章还特别强调:
- AI 系统往往会多次查询语义层;
- 因此必须依赖 cache 与 pre-aggregations;
- 直接让 AI 访问原始数仓,不仅容易产生错误结果,也会带来安全风险。
这很好地把 AI 架构和传统 BI 生产要求连了起来。
与 RAG 结合的架构图
和本教程哪几章最相关
对中国团队的启发
1. 不要把“LLM + 数据库”当作完整方案
很多 PoC 都停留在:
text
自然语言 → Text2SQL → 数仓这篇文章提出了一条更成熟的路线:
text
自然语言 → 语义上下文增强 → 查询语义层 → 返回可信结果2. Meta API 是 AI 接入的关键资产
如果你在编写中文教程或自建 Agent,建议强调:
/v1/meta不是辅助接口;- 它是让上层系统理解语义模型结构的重要入口。
3. AI 场景更需要缓存,而不是更少需要缓存
因为 AI 的查询往往是探索式、多轮式的,这与传统 dashboard 负载不完全相同,但同样需要 acceleration。
我的补充判断
这篇文章最有价值的地方,在于它将“语义层能够降低 hallucination”表述为一条 工程链路,而非营销口号:
- context 来自 semantic model;
- execution 通过 semantic layer;
- performance 靠 cache / pre-aggregations;
- security 通过 access control 保证。
这条链路正是当下大多数企业级 AI analytics 系统所需要的能力。
一句话总结
这篇文章最重要的启发是:语义层之于 LLM,不只是补充知识背景,更是把查询、性能与权限一起收束到可控接口中的工程底座。