精读:The Future of Cube Core and Cube
- 原文:The Future of Cube Core and Cube
- 作者:Artyom Keydunov
- 发布时间:2026-05-14
- 原文链接:https://cube.dev/blog/cube-core-and-cube

这篇为什么值得读
这是近一年里最重要的 Cube 路线说明文之一。它把很多中文读者最容易混淆的问题一次说清楚了:
- Cube Core 还重不重要?
- Cube 商业产品和开源项目是什么关系?
- 为什么现在越来越强调 agentic analytics?
- 为什么官方开始更强调 SQL API?
如果只读一篇用于校准“Cube 到底是什么”,建议优先阅读这一篇。
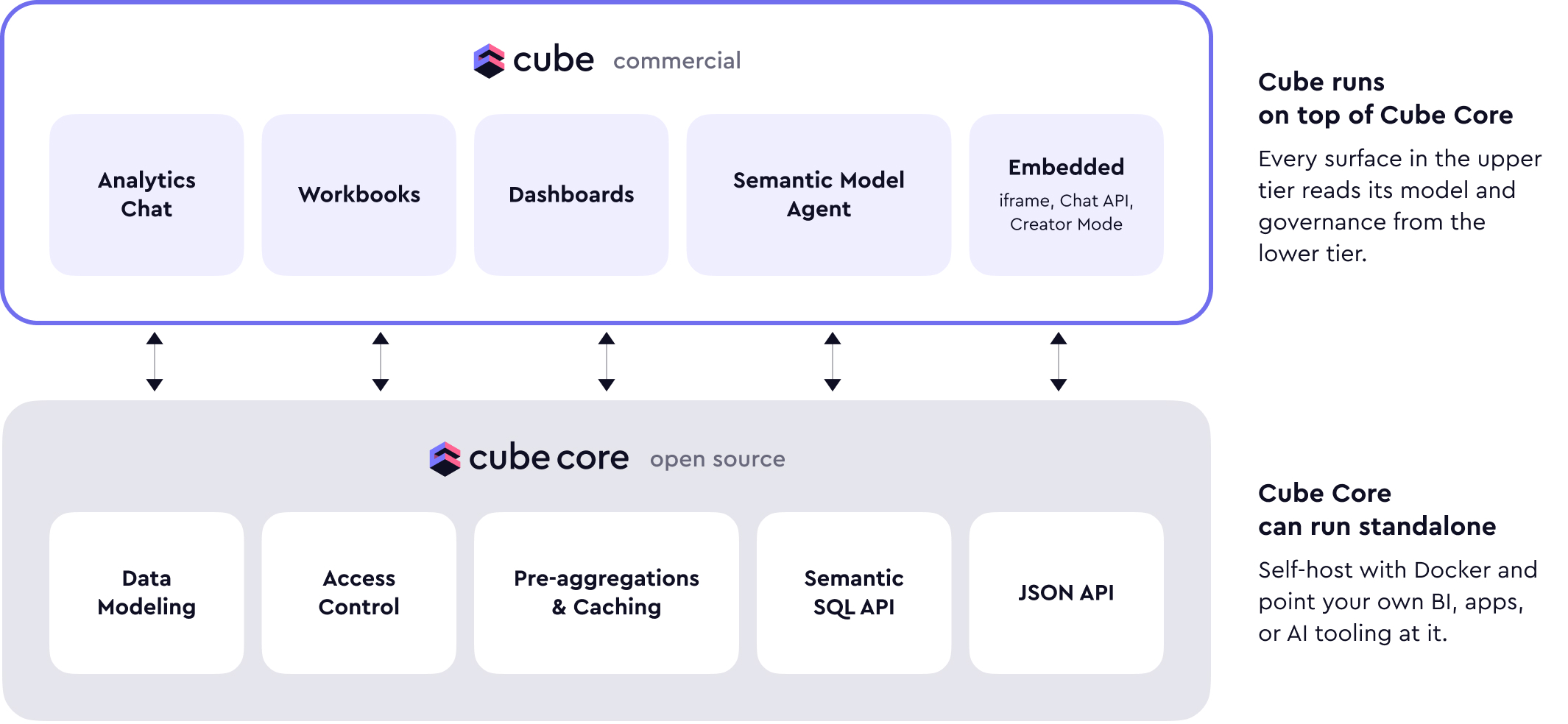
总架构图
核心观点
1. Cube 起点是“把语义层从 BI 工具里拆出来”
原文回顾了一个很关键的历史判断:传统 BI 都内置语义层,但语义层绑定在单一 BI 工具里,不适合工具链越来越碎片化的时代。Cube 最初的价值,就是把这层能力独立出来,用代码定义,再通过 API 给不同消费端复用。
这也是为什么 Cube 早期会被称为 headless BI。
2. AI 时代不会削弱语义层,反而会放大它的重要性
原文明确指出:AI agent 也需要和人类一样的治理上下文。
可以看到,这一观点非常重要。许多团队会把 AI 理解为“替代语义层”,而 Cube 的判断恰好相反:
- 人类需要知道“active customer”怎么定义;
- Agent 也需要知道;
- 人类需要知道行级权限;
- Agent 也需要知道。
因此,agentic analytics 的前提不是跳过语义层,而是更强的语义层。
3. Cube Core 仍然是开源主线,而且负责最核心的底座能力
原文把 Cube Core 定位得很清楚:
- 数据建模
- 访问控制
- 缓存
- 支撑这些能力的 API
也就是说,Cube Core 仍然是语义层内核,而不是被边缘化的历史遗留项目。
4. 商业版 Cube 是“在 Core 之上的完整平台”
商业版并不只是增加了一些连接器,而是补齐了以下能力:
- 前端
- 集成
- 部署自动化
- AI orchestration
- 更完整的 internal BI 与 embedded analytics 体验
因此最稳妥的理解是:
Cube Core = 开源语义层底座
Cube = 基于 Cube Core 的完整 agentic BI / analytics 平台5. 官方对 SQL API 的重视程度明显提高
原文非常明确地给出建议:
- 如果今天新做 Cube Core 项目,优先考虑 SQL API;
- SQL 更有表达力,能在治理与自助分析之间取得更好的平衡;
- 旧的 JSON REST API 不会消失,但不再是新能力的主战场。
这和我们教程主线里“SQL API 正在变成更强主线入口”的判断是一致的。
6. Rust 重写不是枝节,而是核心基础设施升级
文章提到的 Tesseract,说明 Cube Core 不是停留在维护期,而是在继续向:
- 多阶段计算
- 更快编译
- 更强 SQL 生成
- 更稳的性能基础
推进。
和本教程哪几章最相关
对中国团队的启发
1. 做中文教程时,必须把 Core 和商业版分开讲
否则读者会误以为:
- Cube 自带完整 BI 前端;
- 所有新能力都属于开源主线;
- AI / Chat / Workbooks 就是 Cube 的全部。
2. 做选型时,不要只问“能不能自托管”
更关键的问题其实是:
- 你要的是 语义层底座,还是 完整 BI 平台?
- 你有没有团队自己做嵌入式分析前端?
- 你是否愿意自己承担多租户与运维复杂度?
3. 未来的新项目应把 SQL API 放到更高优先级
尤其是当你想同时服务:
- BI 工具
- Notebook
- 自定义数据应用
- AI Agent
时,SQL API 的统一性会越来越有价值。
我的补充判断
这篇文章的重要价值并不只在于“路线图”,还在于它相当明确地说明了:
Cube 不再只是“一个开源分析 API 项目”,而是在用同一套语义层底座同时承载 open-source core 与 full agentic platform 两条线。
对中文读者来说,这能有效避免两个误解:
- 误以为 Cube Core 已经不重要;
- 误以为学习 Cube 就等于学习一个聊天式 BI 产品。
一句话总结
这篇文章最值得保留的结论是:Cube Core 仍是开源语义层底座,Cube 则是在该底座之上构建的完整 agentic analytics 平台;AI 时代让语义层更重要,而不是更不重要。