Blog 专题:AI 与语义层

本专题将 10 篇精读中与 LLM / Agent / 自然语言问数 最相关的内容组织为一条连续主线。
架构图参考
推荐阅读卡片
Semantic Layer: The Backbone of AI-powered Data Experiences
适合建立“AI 为什么需要语义层”这一主线认知。
Semantic Layers are the missing piece for AI-Enabled Analytics
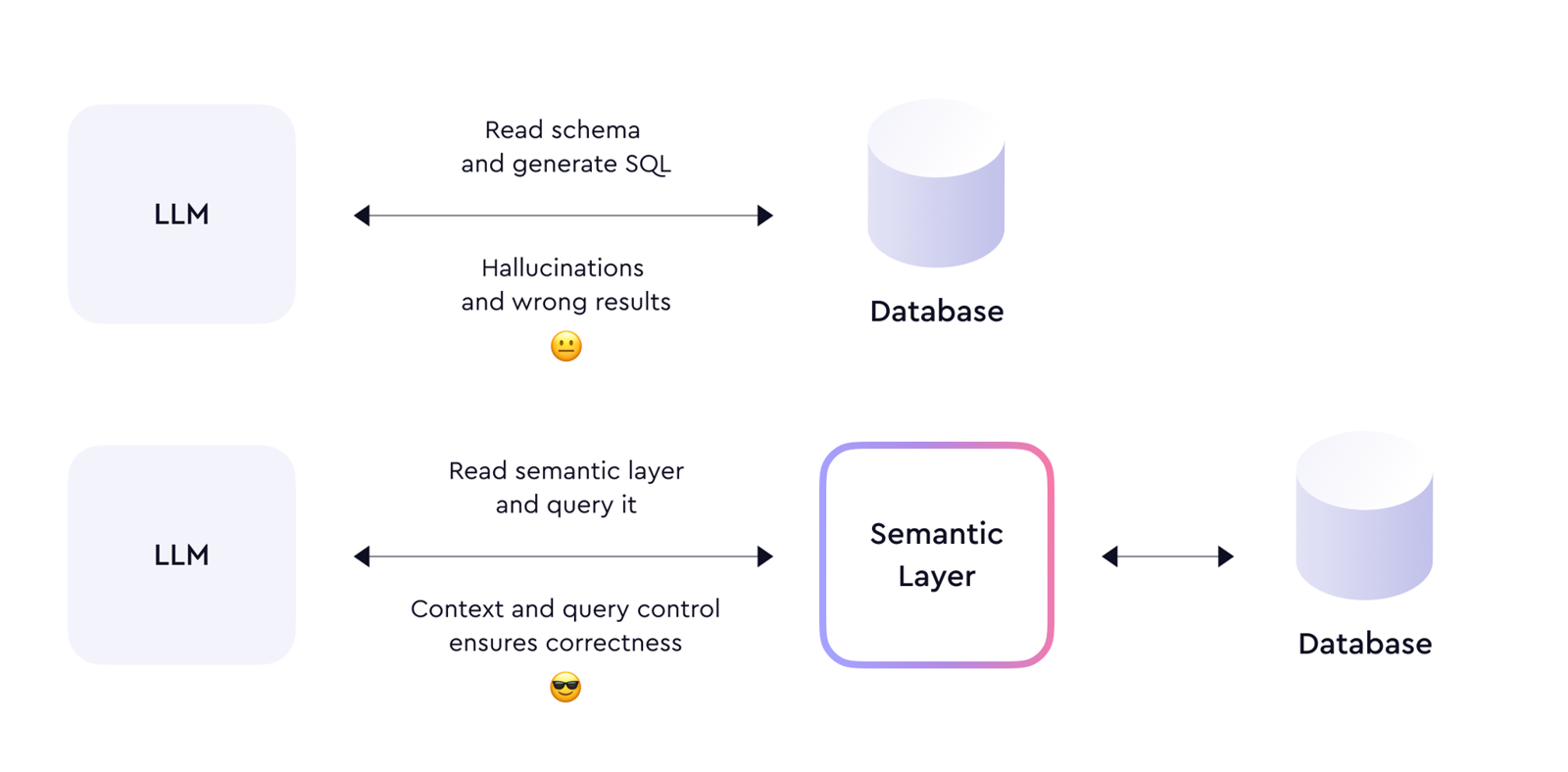
把语义层对 LLM 的价值总结成 context + constraint。

Semantic Layer and AI: The Future of Data Querying with Natural Language
更接近一篇自然语言问数系统架构综述。

The Future of Cube Core and Cube
用于理解 AI 为什么会进一步提升语义层的重要性,而非取代它。
本专题关注的问题
1. 为什么 Agent 不该直连原始表
核心答案来自第一篇与第二篇:
- LLM 需要 context;
- 还需要 constraint;
- 语义层同时提供两者。
2. 为什么语义层不是“可选优化”,而是 AI 数据系统的底座
这些文章共同表达的主线是:
- schema 只是底层结构;
- semantic model 才是业务语义;
- query interface 才是执行约束;
- cache / pre-aggregations 才能保证 Agent 多轮分析可用。
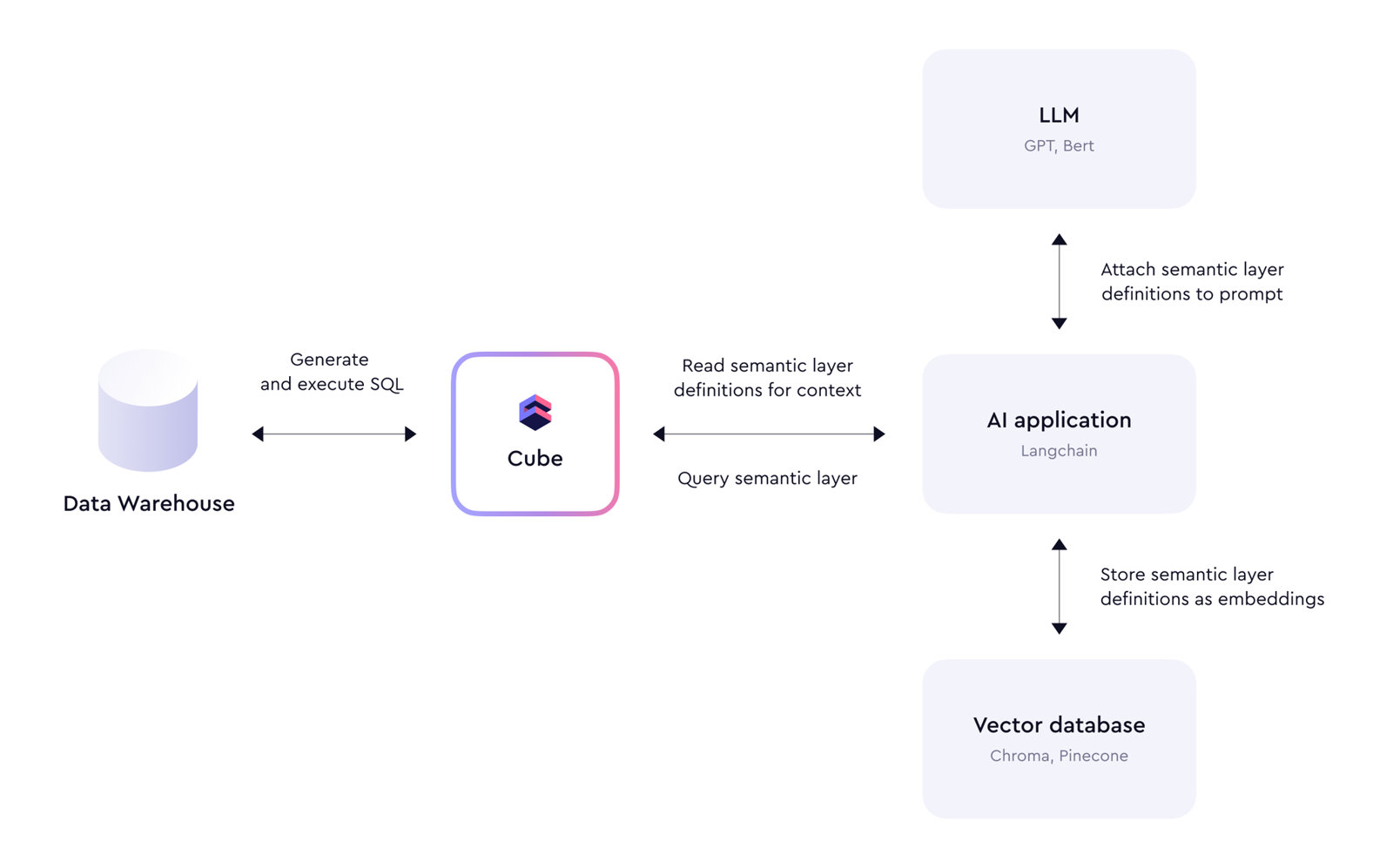
3. 自然语言问数真正需要哪些组件
第三篇尤其适合回答以下问题:
- metadata retrieval
- prompt augmentation
- semantic layer compiler
- API / SQL transpiler
- result explanation
更完整的 AI 架构图
五个关键判断
- LLM 不是天然懂业务口径。
- 只补上下文,不加约束,不够。
- Meta API 是 AI 接语义层的重要入口。
- Agent 的查询模式更依赖缓存与预聚合。
- AI 时代会让语义层更重要,而不是过时。
对应本教程主线
一句话总结
本专题的核心结论是:AI 问数的关键不在于让模型直接生成 SQL,而在于让模型工作在统一语义层之上。